

Spark-数据读取与保存(Scala版)

文件格式
Spark对文件的读取和保存方式都很简单,会根据文件的扩展名选择对应的处理方式
Spark支持的一些常见格式
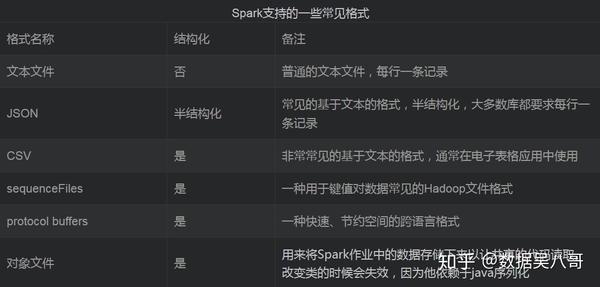

文本文件
当我们将一个文本文件读取为RDD时,输入的每一行都会成为RDD的一个元素,也可以将多个完整的文本文件一次性读取为一个pair RDD,其中键是文件名,值是文件内容。
读取文本文件
只需要使用文件路径作为参数调用SparkContext中的textFile()函数,就可以读取一个文本文件
读取一个文本文件


如果文件足够小,可以使用SparkContext,wholeTextFiles()方法,该方法会返回一个pair RDD,其中键是输入文件的文件名
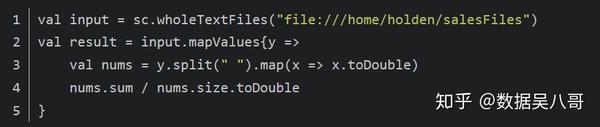

JSON
JSON是一种使用较广的半结构化数据格式,读取JSON数据的最简单的方法可以在所有支持的编程语言中使用。然后使用JSON解释器来对RDD中的值进行映射操作,Scala中也可以使用一个自定义Hadoop格式来操作JSON数据。
在scala中读取JSON
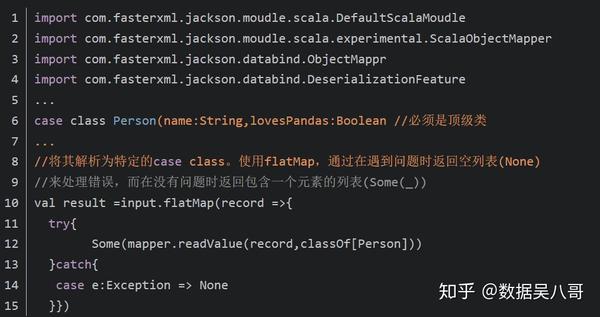

在scala中保存为JSON


逗号分隔值(CSV)与制表符分割值(TSV)
读取CSV
读取CSV/TSV数据和读取JSON数据相似,都需要先把文件当做普通文本文件来读取数据,再对数据进行处理。由于格式标准的缺失,同一个库的不同版本有时也会用不同的方式处理输入数据。
如果你的CSV的所有数据字段均没有包含换行符,你也可以使用textFile()读取并解析数据
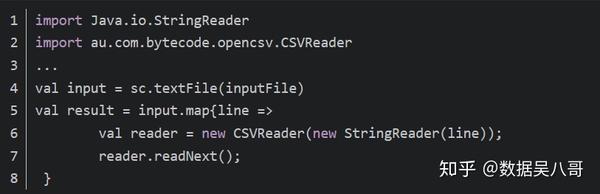

如果在字段中嵌有换行符,就需要完整读入每个文件,然后解析。
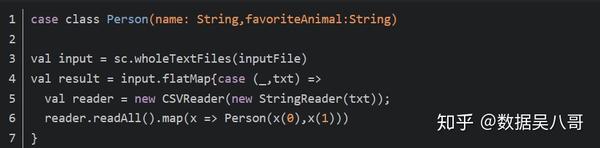

保存CSV
写出CSV/TSV数据很简单,可以通过重用输出编码器来加速


上述的例子中只能在我们知道所有要输出的字段时使用,然而如果一些字段名是在运行时由用户输入决定的,就要使用别的方法了,最简单的方法是遍历所有的数据,提取不同的键,然后分别输出。
SequenceFile
SequenceFile是由没有相对关系结构的键值对文件组成常用的Hadoop格式,SequenceFile文件有同步标记,Spark可以用它来定位到文件中的某个点,然后再与记录的边界对其。这可以让Spark使用多个节点高效的并行读取SequenceFile文件。
读取SequenceFile
Spark有专门用来读取SequenceFile的接口。SparkContext中,可以调用sequenceFile(path,keyClass,valueClass,minPartitions)


保存SequenceFile

