给定关系R和关系S,求R÷S。
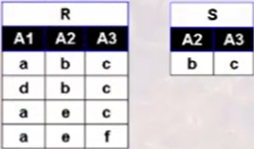
关系R和关系S拥有共同的属性A2、A3 ,
-
首先确定得到的属性为A1。(R÷S得到的属性是
关系R包含而关系S不包含
的属性,即A1)

-
其次确定A1中符合条件的属性值为{a,d}。(关系R中A1的属性值为{a,d},R÷S的结果必然是它的子集,判断当A1为a时,A2和A3属性是否为b和c,发现满足这一条件,因此a被选中,d也是同理被选中)
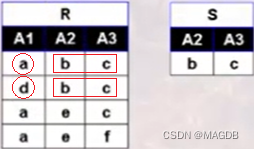
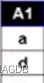
最后得出,R÷S={a,d}
理解的关键是
R包含而S不包含
,当S含有R不含有的属性时,可以忽视该属性

在R关系中A属性的值可以取{ a1,a2,a3,a4 }
a1值对应的集为 { (b1,c2) , (b2,c1) , (b2,c3) }
a2值对应的集为 { (b3,c7) , (b2,c3) }
a3值对应的集为 { (b4,c6) }
a4值对应的集为 { (b6,c6) }
关系S在B、C上的投影为 { (b1,c2) , (b2,c1) , (b2,c3) }
只有a1值对应的象集
包含
关系S的投影集,所以只有a1应该包含在除法结果中A属性里
所以R÷S为

-
数据库关系代数中除运算讲解和SQL语句的实现
r÷s=ΠR−S(r)–ΠR−S((ΠR−S(r))×s–ΠR(r))
r \div s = \Pi_{R-S}(r) – \Pi_{R-S}((\Pi_{R-S}(r)) \times s – \Pi_{R}(r))r÷s=ΠR−S(r)–ΠR−S((ΠR−S(r))×s–ΠR(r))
包含着投影、笛卡尔积、差 关系运算
理解
:
除法
...
⼤数据导论(1)——"⼤数据"相关概念、5V特征、数据类型 在过去的⼗⼏年中,各个领域都出现了⼤规模的数据增长,⽽各类仪器、通信⼯具以及集成电路⾏业的发展也为海量数据的产⽣与存储提供 了软件条件与硬件⽀持。 ⼤数据,这⼀术语正是产⽣在全球数据爆炸式增长的背景下,⽤来形容庞⼤的数据集合。 由于⼤数据为挖掘隐藏价值提供了新的可能,如今⼯业界、研究界甚⾄政府部门等各⾏各业都对⼤数据这⼀研究领域密切关注。 尽管⽬前⼤数据的重要性已被社会各界认同,但⼤数据的定义却众说纷纭,Apache Hadoop组织、麦肯锡、国际数据公司等其他研究者都 对⼤数据有不同的定义。但⽆论是哪种定义都具有⼀定的狭义性。 因此,我们可以从⼤数据的"5V"特征对⼤数据进⾏识别。同时,企业内部在思考如何构建数据集时,也可以从此特征⼊⼿。以下就是⼤ 数据的"5V"特征图。 1. 容量(Volume) 是指⼤规模的数据量,并且数据量呈持续增长趋势。⽬前⼀般指超过10T规模的数据量,但未来随着技术的进步,符合⼤数据标准的数据集 ⼤⼩也会变化。 ⼤规模的数据对象构成的集合,即称为"数据集"。 不同的数据集具有维度不同、稀疏性不同(有时⼀个数据记录的⼤部分特征属性都为0)、以及分辨率不同(分辨率过⾼,数据模式可能会 淹没在噪声中;分辨率过低,模式⽆从显现)的特性。 因此数据集也具有不同的类型,常见的数据集类型包括:记录数据集(是记录的集合,即
数据库
中的数据集)、基于图形的数据集(数据对 象本⾝⽤图形表⽰,且包含数据对象之间的联系)和有序数据集(数据集属性涉及时间及空间上的联系,存储时间序列数据、空间数据 等)。 2. 速率(Velocity) 即数据⽣成、流动速率快。数据流动速率指指对数据采集、存储以及分析具有价值信息的速度。 因此也意味着数据的采集和分析等过程必须迅速及时。 3. 多样性(Variety) 指是⼤数据包括多种不同格式和不同类型的数据。数据来源包括⼈与系统交互时与机器⾃动⽣成,来源的多样性导致数据类型的多样性。根 据数据是否具有⼀定的模式、结构和关系,数据可分为三种基本类型:结构化数据、⾮结构化数据、半结构化数据。 结构化数据,指遵循⼀个标准的模式和结构(conform to a data model or schema),以⼆维表格的形式存储在关系型
数据库
⾥的⾏ 数据。结构化数据是先有结构、后产⽣数据。由于关系型
数据库
发展较为成熟,因此结构化数据的存储、分析⽅法也发展的较为全⾯, 有⼤量的⼯具⽀持结构化数据分析,分析⽅法⼤部门以统计分析和数据挖掘为主。其中,关系型
数据库
(Relational Database)是创 建在关系模型基础上的
数据库
,关系模型即⼆维表格模型,因此⼀个关系型
数据库
包括⼀些⼆维表且这些表之间的具有⼀定关联。关系 型
数据库
可运⽤SQL语⾔通过固有键值提取相应信息。 ⾮结构化数据,是指不遵循统⼀的数据结构或模型的数据(如⽂本、图像、视频、⾳频等),不⽅便⽤⼆维逻辑表来表现。这部分数据 在企业数据中占⽐达,且增长速率更快。⾮结构化数据更难被计算机
理解
,不能直接被处理或⽤SQL语句进⾏查询。⾮结构化数据常以 ⼆进制⼤型对象(BLOB,将⼆进制数据存储为⼀个单⼀个体的集合)形式,整体存储在关系型
数据库
中中;或存储在⾮关系型
数据库
中(NoSQL
数据库
)。其处理分析过程也更为复杂。 半结构化数据,是指有⼀定的结构性,但本质上不具有关系性,介于完全结构化数据和完全⾮结构化数据之间的数据。它可以说是结构 化数据的⼀种,但是结构变化很⼤。因此,为了了解数据的细节,不能将数据简单按照⾮结构化数据或结构化数据进⾏处理,需要特殊 的存储(化解为结构化数据/⽤XML格式来组织并保存到CLOB字段中)和处理技术。半结构化数据包含相关标记,⽤来分隔语义元素 以及对记录和字段进⾏分层。因此,它也被称为⾃描述的结构(以树或者图的数据结构存储的数据)。先有数据,再有结构。两种常见 的半结构化数据:XML⽂件和JSON⽂件。常见来源包括电⼦转换数据(EDI)⽂件、扩展表、RSS源、传感器数据。 除此之外,还有⼀种⽤于描述其他数据的数据,即"元数据"。元数据可说明已知的数据的⼀些属性信息(数据长度、字段、数据列、 ⽂件⽬录等),提供了数据系谱信息(包含数据的演化过程。)、和数据处理的起源。元数据可分为三种不同类型,分别为记叙性元数 据、结构性元数据和管理性元数据,主要由机器⽣成并添加到数据集中。例如数码照⽚中提供⽂件⼤⼩和分辨率的属性⽂件。元数据的 作⽤也类似于数据仓库中的数据字典。 4. 真实性(Veracity) 指数据的质量和保真性。⼤数据环境下的数据最好具有较⾼的信噪⽐。 信噪⽐与数据源和数据类型⽆关。 5. 价值(Value) 即低价值密度。随着数据量的增长,数据
关系模式相当于一张二维表的框架,在这个框架下填入数据,称为关系模式的一个实例,或者叫关系(R)
R(A1,A2,A3..Ai):R是关系名,Ai是关系的属性名。一个关系名对应一张表,关系名对应表名,属性对应表中的列名。
关系模型的简化表示法: R<U,F>
关系规范化
关系模式规范化的作用
关系型
数据库
的设计主要是关系模式的设计。关系模式设计的好坏直接影响关系型
数据库
设计的成败。将关系模式规范化是设计好关系型
数据库
的唯一途径。
未经规范化的
数据库
一般都有下述缺点:
较大的数据冗余,数据一致性差,数据修改复杂,对表进行更新,插入,删除是会报异常。
规范化的作用就在于尽量去除冗余,使数据保持一致,使数据修改简单,除去在表中进行插入、删除时产生的异常,规范化后的表一般都较小。
关系规范化
关系模式的规范化主要由范式来完成。
所谓范式(Normal Form, NF)是指规范化的关系模式。由规范化程度不同而产生不同的范式。根据满足条件不同,经常称某一关系模式R为“第几模式”。
设关系R除以关系S的结果为关系T,则T包含所有在R但不在S中的属性及其值,则T的原则与S的元组的所有组合都在R中。
用象集来定义
除法
:
给定关系R(X,Y)和S(Y,Z)。其中X,Y,Z为属性组。R中的Y与S中的Y可以有不同的属性名,但必须出自相同的域。
R与S的除运算得到一个新的关系P(X),P是R中满足下列条件的元组在X属性列上的投影:元组在X上的分量值x的象集Yx包含S在Y上...
这里记录一下我对
数据库
除运算的
理解
。
在《
数据库
系统概论第五版》的书中是这样定义的。
设关系R除以关系S的结果为关系T,则T包含所有在R但不在S中的属性及其值,且T的元组与S的元组的所有组合都在R中。
这是一个使用比较广泛的例子。
根据这个例子我们应该怎么
理解
除运算呢?
首先R的属性有ABC,S的属性有BCD,所以包含着R中但却不在S中的属性就是A。
所以T的属性里面只有A这一项属性。
其次T的...
https://blog.csdn.net/baidu_22153679/article/details/52454748?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161560641816780274177280%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=161560641816780274177280&biz_id=
之前学
数据库
都只是感觉单纯在学习Sql而已,而sql语法又符合英语的语法,所以并没有觉的难学,直到翻开教材的那一次,各种概念术语搞得我甚是头疼。
闲话少说!众所周知,除运算是整个代数运算中最难
理解
的运算,没有之一。小编也是在学习这块内容的时候绞尽脑汁,在学习除运算之前,先引出象集的概念
通俗来说:象集就是有两个不相交的属性集A,B;属性集A取特定的属性...

