





持之以恒,贵在坚持,每天进步
一点点
!
前言
Presto 作为现在在企业中流行使用的 即席查询 框架,已经在不同的领域得到了越来越多的应用。本期内容,我会从一个初学者的角度,带着大家从 0 到 1 学习 Presto ,希望大家能够有所收获!

 文章目录
文章目录
-
前言
-
1. Presto简介
-
1. 1 Presto概念
-
1.2 Presto 应用场景
-
1.3 Presto架构
-
1.4 Presto 数据模型
-
1.5 Presto 优缺点
-
1.6 Presto、Impala性能比较
-
1.7 官网地址
-
1.8 Prestodb VS Prestosql(trino)
-
2. Presto安装部署
-
2.1 prestosql 版本的选择
-
2.2 集群安装规划
-
2.3 Presto Server 的安装
-
2.4 Node Properties 配置
-
2.5 JVM Config 配置
-
2.6 Config Properties 配置
-
2.7 Log Properties 配置
-
2.8 Catalog Properties 配置
-
2.9 分发安装目录到集群中其它节点上
-
2.10 修改 node.id
-
2.11 修改 work 节点的配置信息
-
2.12 启动服务
-
3、Presto 命令行 Client 的安装
-
4、Presto 的基本使用
-
5、Presto可视化客户端的安装
-
6、Presto的优化
-
6.1 数据存储
-
6.2 SQL查询
-
6.3 注意事项
-
6.4 可能会踩的坑
-
巨人的肩膀
-
小结
-
彩蛋
Presto是 Facebook 推出的一个开源的分布式SQL查询引擎,数据规模可以支持GB到PB级,主要应用于处理 秒级查询 的场景。 Presto 的设计和编写完全是为了解决像 Facebook 这样规模的商业数据仓库的 交互式分析和处理速度 的问题。
注意: 虽然 Presto 可以解析 SQL,但它不是一个标准的数据库。不是 MySQL、Oracle 的代替品,也不能用来处理在线事务(OLTP) 。
Presto 支持 在线数据查询 ,包括 Hive,关系数据库(MySQL、Oracle)以及专有数据存储。一条 Presto 查询可以将 多个数据源的数据进行合并,可以跨越整个组织进行分析 。
Presto 主要用来处理 响应时间小于 1 秒到几分钟的场景 。
Presto 是一个运行在多台服务器上的分布式系统。完整安装包括一个
Coordinator
和多 个
Worker
。由
客户端
提交查询,从 Presto 命令行 CLI 提交到 Coordinator。Coordinator 进行 解析,分析并执行查询计划,然后分发处理队列到 Worker 。
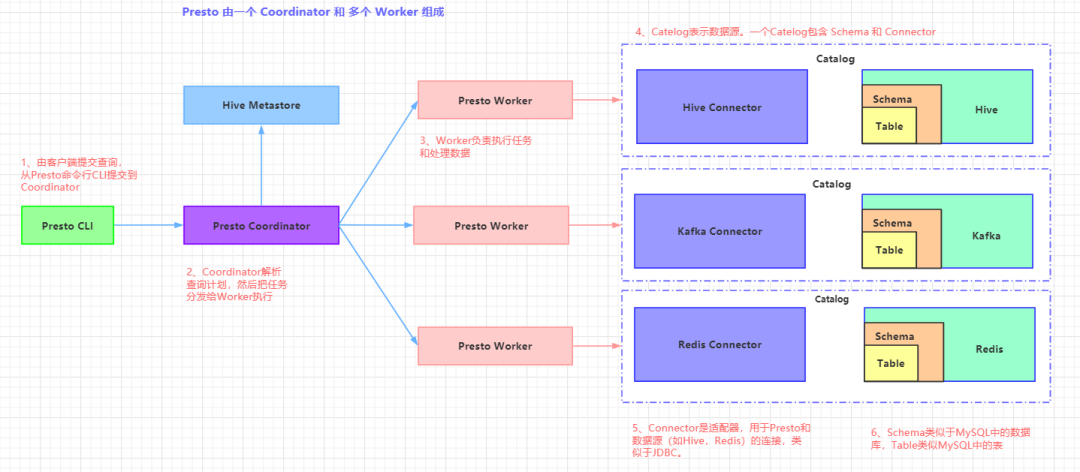 Presto 有两类服务器:
Coordinator
和
Worker
Presto 有两类服务器:
Coordinator
和
Worker
1)
Coordinator
Coordinator 服务器是用来解析语句,执行计划分析和管理 Presto 的 Worker 节点 。 Presto 安装必须有一个 Coordinator 和多个 Worker 。如果用于开发环境和测试,则一个 Presto 实例 可以同时担任这两个角色。
Coordinator 跟踪每个 Work 的活动情况并协调查询语句的执行 。 Coordinator 为每个查询建立模型 ,模型包含多个Stage,每个Stage再转为Task 分发到不同的 Worker 上执行。
Coordinator 与 Worker、Client 通信是通过 REST API 。
2)
Worker
Worker 是负责执行任务和处理数据 。Worker 从 Connector 获取数据。Worker 之间会交换中间数据。Coordinator 是负责从 Worker 获取结果并返回最终结果给 Client。
当 Worker 启动时,会广播自己去发现 Coordinator,并告知 Coordinator 它是可用,随时 可以接受 Task 。
Worker 与 Coordinator、Worker 通信是通过 REST API 。
3)数据源
贯穿下文,你会看到一些术语: Connector 、 Catelog 、 Schema 和 Table 。这些是 Presto 特定的 数据源
-
Connector
Connector 是适配器,用于 Presto 和数据源(如 Hive、RDBMS)的连接
。你可以认为 类似
JDBC
那样,但却是 Presto 的 SPI 的实现,使用标准的 API 来与不同的数据源交互。
Presto 有几个内建 Connector:JMX 的 Connector、System Connector(用于访问内建的 System table)、Hive 的 Connector、TPCH(用于 TPC-H 基准数据)。还有很多第三方的 Connector,所以 Presto 可以访问不同数据源的数据 。
每个 Catalog 都有一个特定的 Connecto r 。如果你使用 catelog 配置文件,你会发现每个 文件都必须包含 connector.name 属性,用于指定 catelog 管理器(创建特定的 Connector 使用)。一个或多个 catelog 用同样的 connector 是访问同样的数据库。例如,你有两个 Hive 集群。你可以在一个 Presto 集群上配置两个 catelog,两个 catelog 都是用 Hive Connector,从而达 到可以查询两个 Hive 集群。
-
Catelog
一个 Catelog 包含 Schema 和 Connector 。例如,你配置JMX 的 catelog,通过JXM Connector 访问 JXM 信息。当你 执行一条 SQL 语句时,可以同时运行在多个 catelog 。
Presto 处理 table 时,是通过表的
完全限定(fully-qualified)名
来找到 catelog。例如, 一个表的权限定名是
hive.test_data.test
,则
test
是表名,
test_data
是 schema,
hive
是 catelog。
Catelog 的定义文件是在 Presto 的配置目录中。
-
Schema
Schema 是用于组织 table 。把 catelog 和 schema 结合在一起来包含一组的表。当通过Presto 访问 hive 或 Mysq 时,一个 schema 会同时转为 hive 和 mysql 的同等概念。
-
Table
Table 跟关系型的表定义一样,但数据和表的映射是交给 Connector。
1) Presto 采取三层表结构:
Catalog
:对应某一类数据源,例如 Hive 的数据,或 MySql 的数据
Schema
:对应 MySql 中的数据库
Table
:对应 MySql 中的表
 2)
Presto
的存储单元包括:
2)
Presto
的存储单元包括:
Page
:多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
Block
:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接 presto。
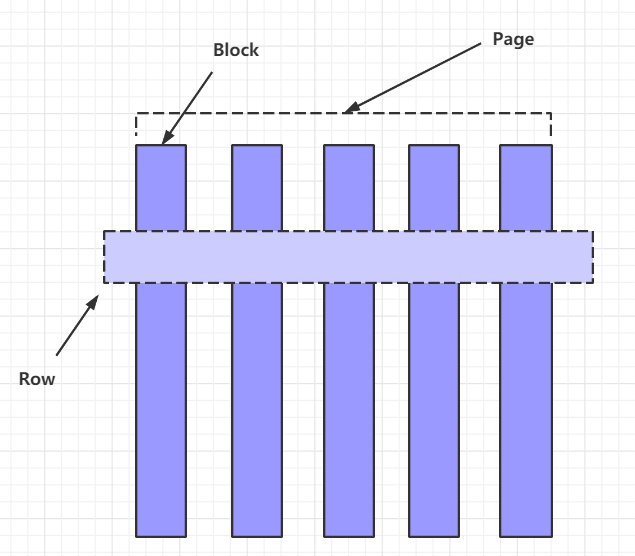 3)不同类型的 Block:
3)不同类型的 Block:
( 1) Array 类型 Block,应用于固定宽度的类型 ,例如 int,long,double。block 由两部分组成:
-
boolean valueIsNull[]
表示每一行是否有值 。 -
T values[]
每一行的具体值
(2) 可变宽度的 Block,应用于 String 类数据 ,由三部分信息组成
-
Slice
:所有行的数据拼接起来的字符串 -
int offsets[]
:每一行数据的起始偏移位置。每一行的长度等于下一行的起始偏移减去当 前行的起始偏移。 -
boolean valueIsNull[]
: 表示某一行是否有值。如果有某一行无值,那么这一行的偏移量 等于上一行的偏移量。
(3) 固定宽度的 String 类型的 block,所有行的数据拼接成一长串 Slice,每一行的长度固定 。
(4) 字典 block:对于某些列,distinct 值较少,适合使用字典保存 。主要有两部分组成:
字典
,可以是任意一种类型的 block(甚至可以嵌套一个字典 block),block 中的每一行按照顺序排序编号。
int ids[]
表示每一行数据对应的 value 在字典中的编号。在查找时,首先找到某一行的 id, 然后到字典中获取真实的值。
学习一个新的框架,免不了来探讨一下它的优缺点:
通过下面一张图,我们来看看 Presto 中 SQL 运行过程: MapReduce vs Presto
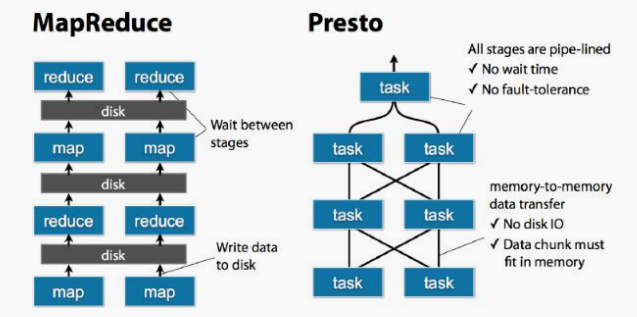 我们可以很明显地感受到,
Presto 使用内存计算,减少与硬盘交互
我们可以很明显地感受到,
Presto 使用内存计算,减少与硬盘交互
1) Presto 与 Hive 对比,都能够处理 PB 级别的海量数据分析,但 Presto 是基于内存运算,减少没必要的硬盘 IO,所以更快 。
2) 能够连接多个数据源,跨数据源连表查,如从 Hive 查询大量网站访问记录,然后从 Mysql 中匹配出设备信息 。
3) 部署也比 Hive 简单,因为 Hive 是基于 HDFS 的,需要先部署 HDFS 。
找了张对比图,大家感受下:
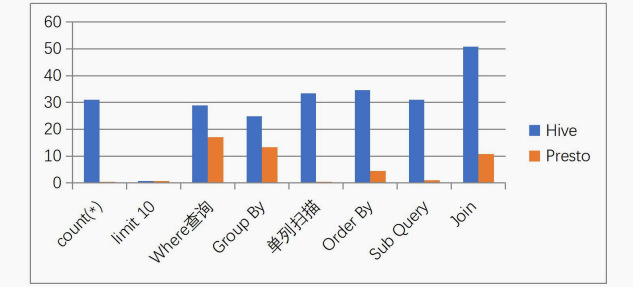
1) 虽然能够处理 PB 级别的海量数据分析,但不是代表 Presto 把 PB 级别都放在内存中计算的 。而是根据场景,如 count,avg 等聚合运算,是 边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高 。但是 连表查,就可能产生大量的临时数据,因此速度会变慢,反而 Hive此时会更擅长 。
2)为了达到实时查询,可能会想到用它直连 MySql 来操作查询,这效率并不会提升, 瓶颈依然在 MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。
Presto 和 Impala这两种典型的 内存数据库 之间具体的性能测试比较就不详细展开叙述,感兴趣可以去看这篇链接:https://blog.csdn.net/u012551524/article/details/79124532
我就说下总结的结论:
他们的共同点就是吃内存,当然在内存充足的情况下,并且有规模适当的集群,性能应该会更可观。并且从几次性能的比较查询来看, Impala性能稍领先于presto,但是presto在数据源支持上非常丰富 ,包括hive、图数据库、传统关系型数据库、Redis等
大家也可以根据上面的链接,自己也尝试去做下对比测试。
就在 2020 年 12 月 27 日,prestosql 与 facebook 正式分裂,并改名为
trino
。分裂之前和之后的官网分别是:https://prestosql.io/ 和 https://trino.io。
根据目前社区活跃度和使用广泛度,更加推荐 prestosql。具体的区别详见:
http://armsword.com/2020/05/02/the-difference-between-prestodb-and-prestosql/
在 presto330 版本里已经提到,jdk8 只支持到 2020-03 月发行的版本.详情参考:https://prestosql.io/docs/current/release/release-330.html。在 2020 年 4 月 8 号 presto 社区发布的 332 版本开始,需要 jdk11 的版本.由于现在基本都使 用的是 jdk8,所以我们选择 presto315 版本的,此版本在 jdk8 的环境下是可用的。如果我们生产环境是 jdk8,但是又想使用新版的 presto,可以为 presto 单独指定 jdk11 也可使用。
| host | coordinator | worker |
|---|---|---|
| node01 | √ | × |
| node02 | × | √ |
| node03 | × | √ |
1、安装包下载地址:
https://repo1.maven.org/maven2/io/prestosql/presto-server/315/presto-server-315.tar.gz
2、将
presto-server-315.tar.gz
上传到服务器上,这里导入到 node01 服务器上的
/export/software/
目录下,并解压至
/export/servers/
目录下:
[root@node01 software]# tar -zvxf presto-server-315.tar.gz -C /export/servers/
3、创建 presto 的数据目录 ( presto 集群的每台机器都要创建 ),用来存储日志这些
[root@node01 presto-server-315]# mkdir -p /file/data/presto
4、在安装目录 export/servers/presto-server-315 下创建 etc 目录,用来存放各种配置文件
[node01@node01 presto-server-315]# mkdir etc
在
/export/servers/presto-server-315/etc
路径下,配置 node 属性(注意:
集群中每台 presto 的 node.id 必须不一样
,后面需要修改集群中其它节点的 node.id 值)
[root@node01 etc]# vim node.properties
#环境名称,自己任取.集群中的所有 Presto 节点必须具有相同的环境名称.
node.environment=develop
#支持字母,数字.对于每个节点,这必须是唯一的.这个标识符应该在重新启动或升级 Presto 时保持一致
node.id=1
#指定 presto 的日志和其它数据的存储目录,自己创建前面创建好的数据目录
node.data-dir=/file/data/presto
在
/exports/servers/presto-server-315/etc
目录下添加
jvm.config
配置文件,并填入如下内容
#参考官方给的配置,根据自身机器实际内存进行配置
-server
#最大 jvm 内存
-Xmx16G
#指定 GC 的策略
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-XX:ReservedCodeCacheSize=256M
Presto 是由一个
coordinator
节点和多个
worker
节点组成。由于在单独一台服务器上配置 coordinator ,有利于提高性能,所以在 node01上配置成 coordinator,在 node02,node03 上配 置为 worker(如果实际机器数量不多的话可以将在协调器上部署 worker.)在
/export/servers/presto-server-315/etc
目录下添加
config.properties
配置文件
# 该节点是否作为 coordinator,如果是 true 就允许该 Presto 实例充当协调器
coordinator=true
# 允许在协调器上调度工作(即配置 worker 节点).为 false 就是不允许.对于较大的集群,协调器上的处理工作可能会影响查询性能,因为机器的资源无法用于调度,管理和监视查询执行的关键任务
# 如果需要在协调器所在节点配置 worker 节点改为 true 即可
node-scheduler.include-coordinator=false
# 指定 HTTP 服务器的端口.Presto 使用 HTTP 进行所有内部和外部通信
http-server.http.port=8080
# 每个查询可以使用的最大分布式内存量
query.max-memory=50GB
#查询可在任何一台计算机上使用的最大用户内存量
query.max-memory-per-node=1GB
# 查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入器和网络缓冲区等在执行期间使用的内存
query.max-total-memory-per-node=2GB
# discover-server 是 coordinator 内置的服务,负责监听 worker
discovery-server.enabled=true
# 发现服务器的 URI.因为已经在 Presto 协调器中启用了 discovery,所以这应该是 Presto 协调器的 URI
discovery.uri=http://node01:8080
日志配置文件:
etc/log.properties
。类似Java的日志级别,包括
INFO
、
DEBUG
、
ERROR
。
com.facebook.presto=INFO
Presto 可以支持多个数据源,在 Presto 里面叫 catalog,这里以配置支持 Hive 的数据源为例,配置一个 Hive 的 catalog :
#在 etc 目录下创建 catalog 目录
[root@node01 etc]# mkdir catalog
Hive 的 catalog:
[root@node01 catalog]# vim hive.properties
#代表 hadoop2 代版本,并不是单单指 hadoop2.x 的版本,而是 hadoop 第二代.固定写法
connector.name=node02
#指定 hive 的 metastore 的地址(hive 必须启用 metastore)
hive.metastore.uri=thrift://node01:9083
#如果 hdfs 是高可用必须增加这个配置.如果不是高可用,可省略.如果 Presto 所在的节点>没 有安装 Hadoop,需要从其它 hadoop 节点复制这些文件到 Presto 的节点
hive.config.resources=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml, /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml
hive.allow-drop-table=true
hive.storage-format=ORC
hive.metastore-cache-ttl=1s
hive.metastore-refresh-interval=1s
hive.metastore-timeout=35m
hive.max-partitions-per-writers=1000
将 node01 上配置好的 presto 安装包分发到集群中的其它节点(这里使用的是自己写的分发脚本)
[root@node01 servers]# xsync script /export/servers/presto-server-315/
修改 node02 和 node03 机器上 node.properties 配置文件中的 node.id (因为每台机器 node.id 必须要不一样)
[root@node02 etc]# vim node.properties
node.id=2
[root@node03 etc]# vim node.properties
node.id=3
修改 worker 节点(即 linux122 和 linux123 机器)上的 config.properties 配置文件里面的配置内容与 coordinator 所在的节点是不一样的
#该节点是否作为 coordinator,因为是 worker 节点,这里是 false
coordinator=false
#访问端口,可以自己指定
http-server.http.port=8080
#每个查询可以使用的最大分布式内存量
query.max-memory=50GB
#查询可在任何一台计算机上使用的最大用户内存量
query.max-memory-per-node=1GB
#查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写 入器和网络缓冲区等在执行期间使用的内存
query.max-total-memory-per-node=2GB
#指定 discovery-server 的地址,这样 worker 才能找到它.与上面的端口须一致
discovery.uri=http://node01:8080
启动脚本在安装目录的
bin/launcher
目录下,我们可以使用如下命令作为一个后台进程启动:
bin/launcher start
另外,也可以用在前台启动的方式运行,日志和目录输出将会写入到
stdout/stderr
(可以使用类似
daemontools
的工具捕捉这两个数据流)
bin/launcher run
启动完之后,日志将会写在
var/log
目录下,该目录下有如下文件:
-
launcher.log
:这个日志文件由 launcher 创建,并且server的stdout和stderr都被重定向到了这个日志文件中。这份日志文件中只会有很少的信息,包括:
在server日志系统初始化的时候产生的日志和JVM产生的诊断和测试信息。
server.log
:这个是 Presto 使用的主要日志文件。一般情况下,该文件中将会包括
server初始化失败时产生的相关信息
。
http-request.log
:这是
HTTP请求的日志文件
,包括server收到的每个HTTP请求信息。
启动成功之后,我们可以通过
jps
查看到多了一个 PrestoServer 的进程。
[root@node01 etc]# jps
6051 PrestoServer
此时我们就可以通过
ip:端口
的方式访问到 presto 的
webui
界面。
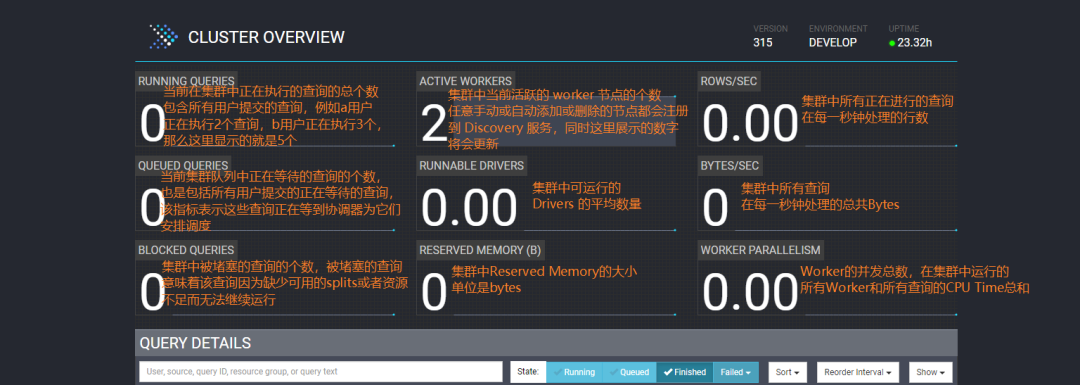
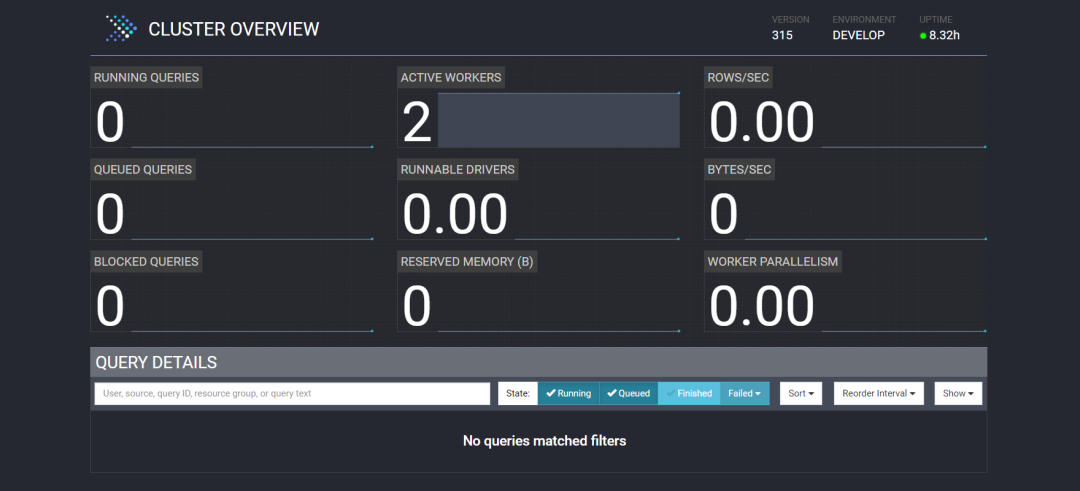 关于
关于
webui
中
各项指标的含义
,我整理了2张图,大家可以借鉴一下
 另外,关于 Stage,Task 阶段的各参数指标含义,就不细讲了,更多内容详情见官网....
另外,关于 Stage,Task 阶段的各参数指标含义,就不细讲了,更多内容详情见官网....
Presto 的 命令行 Client 下载步骤也很简单:
1、下载 Presto 的客户端(下载 presto 对应的版本)👉https://repo1.maven.org/maven2/io/prestosql/presto-cli/315/presto-cli-315-executable.jar
2、将
presto-cli-315-executable.jar
上传至服务器,放在 node01 的
/export/servers/presto-server- 315/bin
目录下
3、为方便使用,修改 jar 包名称为 presto
[root@node01 bin]$ mv presto-cli-315-executable.jar presto
4. 给文件增加执行权限
[root@node01 bin]# chmod +x presto
1、 启动 presto 客户端并选择连接的数据源(这里以 hive 为例)
[root@node01 bin]$ ./presto \
--server node01:8080 \
--catalog hive \(可选)
--schema test \(可选)
--user xiaobai (可选)
说明
:
-- server 指定的是
coordinator
的地址