

AutoGPT 横空出世,会成为 AI 领域中的下一大趋势吗?
关注者
779
被浏览
464,430
82 个回答


创意非常好,但想成为趋势还需要更便宜的大脑(GPT4),更高效的记忆(向量数据库)和更完备的架构(异步通信)。
想体验的可以试试第三个,暂时免费:


它虽然没有实体的身体,但却可以在互联网上自如地游走,收集和分析信息。AutoGPT的核心竞争力主要来自两方面:一是GPT-4的推理预测能力,二是vector database向量数据库的长短期记忆能力。
这就是一个它的一个案例展示:
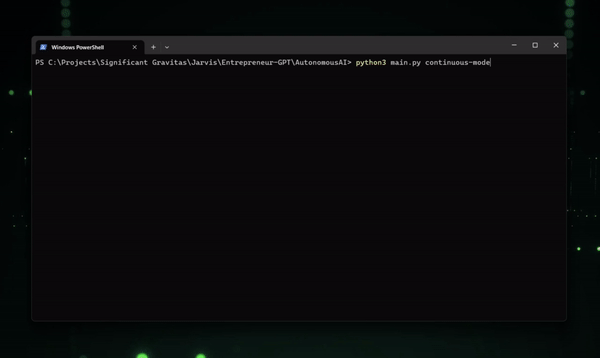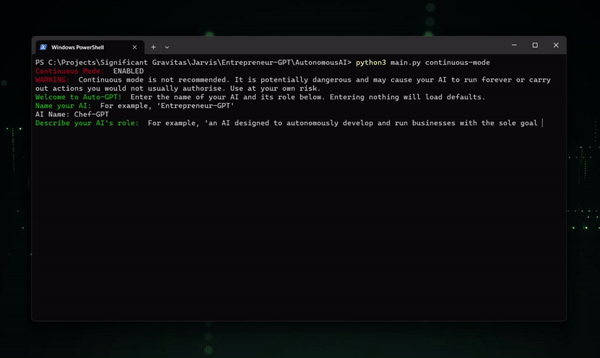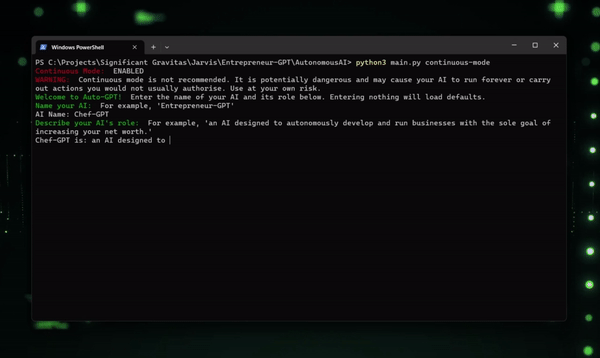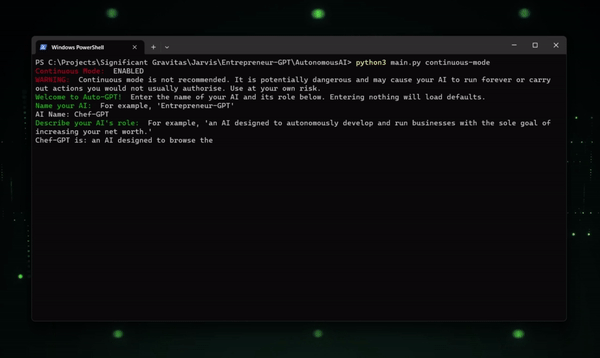
当你给AutoGPT一个任务时,它会利用GPT-4(或者GPT-3.5)对任务进行深入分析,将其拆解成多个子任务。接下来,它会根据你授权的权限范围,运用它强大的分析和解决问题能力,逐步完成这些子任务。
比如你让它做一个网站,或者完成一份行业分析报告。
AutoGPT之所以能够胜任这些复杂任务,主要归功于以下两个关键技术:
- GPT-4:GPT-4为AutoGPT提供了强大的文本分析、理解和推理能力。这意味着它能够快速理解任务需求,准确把握任务中的关键信息,并运用推理能力为任务提供合适的解决方案。
- 向量数据库(vector database):向量数据库作为AutoGPT的核心记忆系统,负责存储和管理各种长短期信息。这种数据库的优势在于它可以高效地整合和检索大量数据,从而让AutoGPT在执行任务时具备丰富的知识储备和实时反馈能力。
GPT-4就不说了,就说这个向量数据库,绝对是目前最适合的解决方案,它厉害就厉害在不仅可以存储大量的信息作为记忆承载体,可以通过向量化数据,将各种时间距离长度的相关信息提取出来进行合并推理以及思考。
其中AutoGPT用到的就是pinecone这个向量数据库。
简单来说,如果你有一长段记忆,现在的记忆和最开始的记忆关联度最高,如果是传统的方法,你得遍历一遍所有记忆才可以找到最开始的记忆,但是向量搜索可以将数据向量化,然后去计算「夹角」的大小,然后根据这个值来判断相似度。
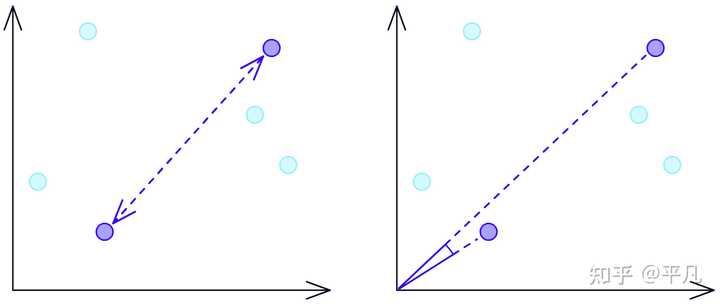
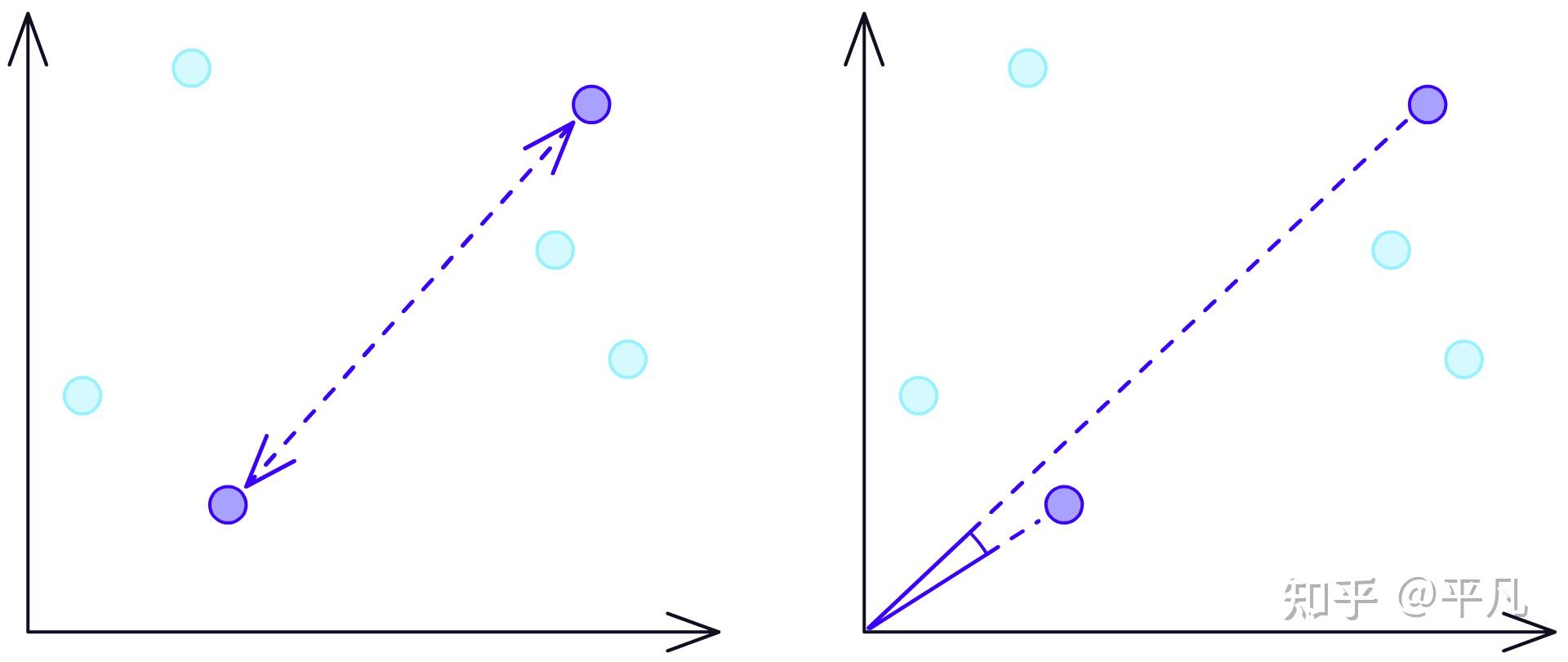
更多的内容请看参考文章。

我和好兄弟 @平凡 在chatgpt开放api的那一刻就在琢磨autogpt的事情了。
实际上我们在使用算法迭代过程中已经用它进行了一些实验,并希望通过它来进行与商业,科技,学术,个人IP的结合。并且目前我们已经生成了智慧星球,虽然其中并没有添加太多内容,但后续我们会逐步进行开发。


什么是Autogpt?
目前的 AutoGPT 通过 API 结合了 GPT-3.5 和 GPT-4,允许创建根据自己的提示进行迭代的项目,并审查每次迭代以改进和构建它。这到底是如何工作的?
Autogpt的要求:
- 人工智能名称
- 人工智能角色
- 目标(最多五个)
例如:
- 名称 : 一言米其林-GPT
- 作用 :一种旨在在网络上找到普通食谱并将其变成米其林星级质量食谱的 AI。
- 目标 1 :在网上找到一个简单的食谱
- 目标 2 :将这个简单的食谱变成米其林星级品质的版本。
一旦 AutoGPT 达到了描述和目标,它就会开始做自己的事情,直到项目达到令人满意的水平。
AutoGPT 的反馈循环如下所示:
- 计划
- 批评
- 行为
- 阅读反馈
-
计划
那么 AutoGPT 有什么好处呢?首先,重要的是要注意 GPT 有能力使用 GPT-4 编写自己的代码。它还执行 Python 脚本,使其能够递归地调试、开发、构建和持续自我改进。没错,AutoGPT 有自我改进的能力。
我记得我前段时间和平凡聊的时候,就说了苹果错过了一个大时代,Siri本是最有能力创造类个人人工智能项目的语音机器人,因为它能实时接收无数信息并进行处理,但是苹果在库克接手后像是裹上了小脚,没有在人工智能板块做任何极致的创新。
那么更专业的量身定做的GPT生成模型当然会更有意思,更疯狂。
所以这是一个开端,是不是趋势?用脚就可以判定。