

因果推断 PSM方法 +Python 代码实战

一、模型引入
1.1 应用场景
以一款学习APP「得到」为例,产品经理想量化上线「签到功能」后对用户留存率的提升,请同学们开动小脑瓜,应该怎么计算呢?
△留存率 = 使用了签到功能的用户留存率 - 未使用签到功能的用户留存率? Nonono
实际上使用了签到功能的用户是不是本身就比未使用签到功能的用户更活跃?这样一来就会带来△留存率的高估。
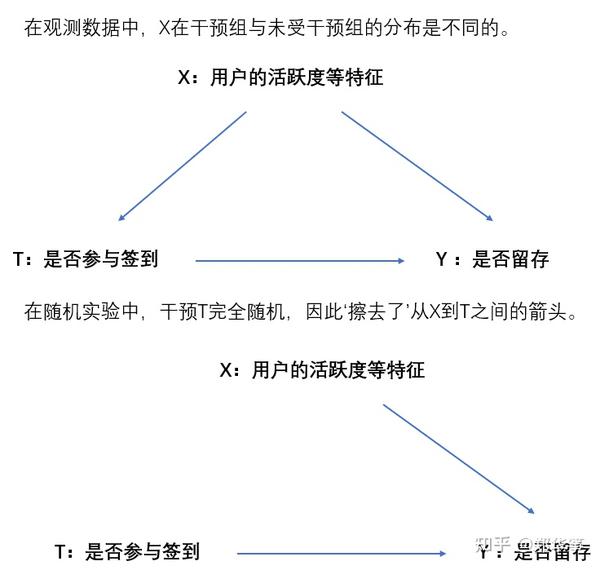
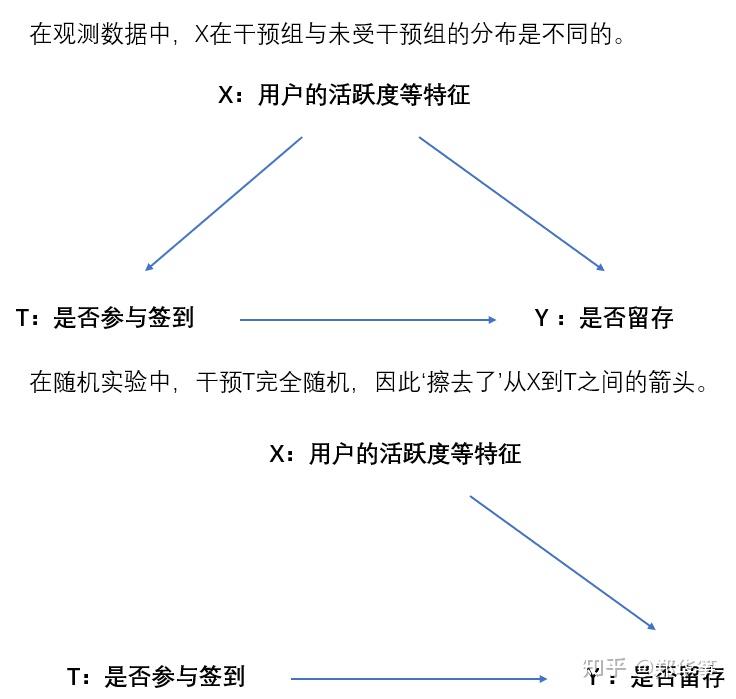
因此我们引入倾向性匹配法PSM(Propensity Score Matching):在观测数据中,由于种种原因,混杂变量(Confounding Variables,如上图中的X)较多,倾向性匹配得分能够减少混杂变量的影响,使得策略组和对照组进行更合理的比较。
PSM测算的目标是ATT(Average Treatment effect on the Treated),估计ATT最理想的办法就是找到在平行时空中的自己,并这个自己没有被干预,从而作差得到ATT。AB实验中的处理组和对照组可直接作差得到ATT,然而当前无法作差,因此我们需要找到影响个体是否 产生干预的 、 可观测的 混淆因子X,利用处理组和对照组中的「相似」样本作差得到ATT的无偏估计。
假设该功能11-01上线,需要评估该功能带来的△人均活跃天数(7天内),请问哪两个样本更相似?
| 用户id | 10月活跃天数 | 10月充值金额 | 年龄 | 性别 |
|---|---|---|---|---|
| 1 | 13 | 100 | 40 | 男 |
| 2 | 5 | 20 | 38 | 女 |
| 3 | 20 | 90 | 45 | 男 |
用户1和用户3在感性上就是更相似的,但我们需要用更量化的办法来得到「相似」的结论。
因此我们引入PSM模型(Propensity Score Matching),顾名思义,PSM就是用「倾向性得分」来对两个样本实现「匹配」
1.2 模型适用场景
- 无法进行AB实验时(时间紧/政策or道德or安全不允许)
- 样本稀释(例如 快手上线了主播连麦功能,但使用率较低,直接对比实验组控制组得不到显著差异)
1.3 模型局限性
- 模型样本量足够大,匹配完后的处理组和对照组有80%的common support,否则损失较多的观测数据,导致样本不具备代表性
- 只能均衡可以观测的变量,不能均衡未观测变量和由于样本选择偏差的剩余混杂因素(AB实验可以均衡所有因素)
- 倾向得分匹配将许多协变量综合成倾向得分值p-score,由此可能导致倾向得分值接近而协变量差异更大,建议匹配前根据给定 p(X) 检验X分布是否均衡
1.4 模型假设
- CIA(条件独立性假设):在给定了一系列可观测的协变量X之后,潜在结果Y与干预T之间独立,可以再次回想一下之前的图,即排除掉了从X→T的影响
Y\bot T| X
二、PSM详细步骤
2.1 数据处理
从生产环境导出的数据往往并不完美,有大量影响分析的缺失值和异常值,我们要先对数据进行处理。
1)数据质量问题:
字段类型问题,数值型存成字符型,日期格式存成字符型
字段脏乱问题,字段里有空格、分隔符等
字段的业务逻辑:如-999,0,null等都需要与表负责人或业务进行进一步确认(年龄可能会出现100+等情况)
2)数据质量分布:
连续型变量:数量、均值、标准差、分位数
离散型变量:各类别出现次数
数据缺失:变量覆盖率小于60%的可以直接删除,如果变量非常重要不能删除/填充率高于60%,可以将缺失值进行单独的分箱
%load_ext autoreload
%autoreload 2
%matplotlib inline
--包的导入
import warnings
warnings.filterwarnings('ignore')
from pymatch.Matcher import Matcher
import pandas as pd
import numpy as np
#数据导入
path = "misc/loan.csv"
data = pd.read_csv(path)
#数据处理
test = data[data.loan_status == "Default"]
control = data[data.loan_status == "Fully Paid"]
test['loan_status'] = 1
control['loan_status'] = 02.2 特征选择
1)选取原则:
- 应该包括同时影响T(treatment)和因变量(Y)的混淆变量
- 不应该包含受T影响的变量
- 倾向得分的根本目的不是为了要准确地估计参与处置的概率,因此p-score模型的AUC重要性不高
问题:如果加入了只影响Y的变量,那么对结果有什么影响?大家可以在评论区讨论答案。
2)选取特征:可以直接用户画像分析的相关特征,加以取舍

2.3 倾向分计算
与AB方法类似,PSM是用p-score来拉齐用户的‘AA阶段’,此处由于并未上线实验,我们称之为‘观察阶段’
- 选取每个用户在 观察阶段 的特征进行「逻辑回归」或者「Xgb」来为每个用户打分,计算个体进入策略组的概率
因变量Y:用户是否被干预,1 or 0
自变量X:βX,其中X为协变量(向量)
P(T = 1|X)= \phi(βX)
通过logit模型,我们获得了处理组和对照组内每个用户的得分,比如说在处理组内的用户1与对照组内的用户2的得分是「高度接近」的,即两者匹配(Matching)
# exclude中可以填写需要被排除的参数,例如user_id
m = Matcher(test,
control,
yvar="loan_status", exclude=[])
#Formula:
#loan_status ~ funded_amnt+funded_amnt_inv+grade+installment+int_rate+loan_amnt+sub_grade+term
#n majority: 20000
#n minority: 2000
# 设定随机种子,确保结果的可复现性
np.random.seed(20221202)
# 得到倾向性匹配得分