import random
import numpy as np
import open3d as o3d
total_cnt = 10000
rate = 0.3
max = 10
MAXX, MAXY, MAXZ = 3, 4, 7
repeat_cnt = int(total_cnt * rate)
random.seed(10)
def gene_one_point(flag=1):
if flag == 1:
pts = np.array(np.random.random(size=(3,)) * max)
else:
x = np.random.random() * MAXX
y = np.random.random() * MAXY
z = np.random.random() * MAXZ
pts = np.array([x, y, z])
return pts
def point_generator(total_cnt):
result = []
for i in range(total_cnt):
pts = gene_one_point(flag=1)
result.append(list(pts))
return result
origin_points = point_generator(total_cnt)
print(type(origin_points), len(origin_points), origin_points[:5])
def repeat_point_generator(origin_points, total_cnt):
result = []
set_points = set()
for x in origin_points:
set_points.add(str(x[0]) + '_' + str(x[1]) + '_' + str(x[2]))
result = [x for x in origin_points]
while (len(result) < total_cnt):
pts = pts = gene_one_point(flag=1)
key = str(pts[0]) + '_' + str(pts[1]) + '_' + str(pts[2])
if key in set_points:
continue
else:
set_points.add(key)
result.append(list(pts))
return result
points2 = repeat_point_generator(origin_points[:repeat_cnt], total_cnt)
print(type(points2), len(points2), points2[:5])
pcd = o3d.geometry.PointCloud()
points = o3d.utility.Vector3dVector(origin_points)
pcd.points = points
pcd.paint_uniform_color([1, 0, 0])
pcd2 = o3d.geometry.PointCloud()
pcd_points = o3d.utility.Vector3dVector(points2)
pcd2.points = pcd_points
pcd2.paint_uniform_color([0, 1, 0])
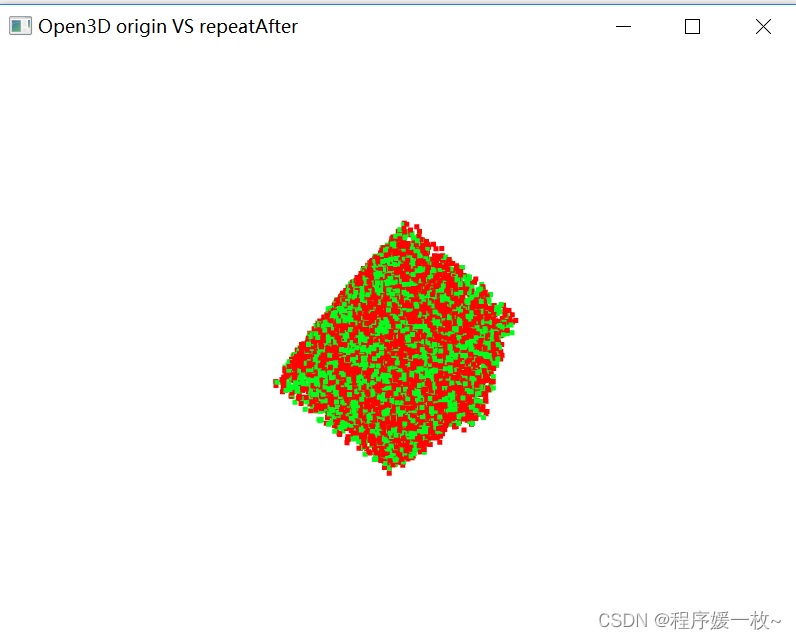
o3d.visualization.draw_geometries([pcd, pcd2], "Open3D origin VS repeatAfter",
width=800,
height=600, left=50,
top=50,
point_show_normal=False, mesh_show_wireframe=False,
mesh_show_back_face=False)
np_origin = np.array([str(x[0]) + '_' + str(x[1]) + '_' + str(x[2]) for x in origin_points])
np_origin2 = np.array([str(x[0]) + '_' + str(x[1]) + '_' + str(x[2]) for x in points2])
inters = np.intersect1d(np_origin, np_origin2)
print('inter: ', len(inters))
这篇博客源于博友的提问,本来不打算周末整的,刚好电脑在旁边没啥事,那就开整吧。np.random 生成随机点(提供了俩种方法,1. xyz限制都是0~MAX值,2. xyz分别限制最大值为0~MAXxyz)第一堆生成完成后,第2堆确定的是重复的点,然后生成剩余的点,生成过程要注意判断不能生成已经有了的点open3d可视化及计算验证重复率。
该代码利用python(numpy)生成ply文件,并将三维点云数据写入ply文件。生成的ply文件可以直接用meshlab打开查看点云。
这个积分太高了,我重新上传了一份,链接:
https://download.csdn.net/download/weixin_41457494/11438608
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
一、图像处理入门
顾名思义,图像处理可以简单地定义为在计算机中(通过代码)使用算法对图像进行处理(分析和操作)。它有几个不同的方面,如图像的存储、表示、信息提取、操作、增强、恢复和解释。在
本项目参考的版本是Pytorch官方torchvision模块中的faster_rcnn源码。也可以在ipynb文件中输入,按住Ctrl+鼠标右键,点击Go to Definition就可以打开,这两个是一样的。
但是这个其实只是代码的一部分,关于训练的代码在Pytorch官方vision仓库下的可以找到(点此链接)。打开项目地址,README.md中有写文件结构:├── : 特征提取网络,可以根据自己的要求选择。这里可使用或
├── : Faster R-CNN网络主要源码部分(包括Fast R
在进行分类和聚类问题时,我们需要使用数据来测试算法的效果,此时采用生成两类不同的二维点(如下图)的方式的最直观的。
此时,我们可以很清晰的看到,蓝色的点为一类,红色的点为一类。我们可以使用这样的数据来测试我们算法的效果。
本文将阐述如何生成这样的二维点,并加上标签,最后整理成dataframe的格式。(如果时聚类问题,那么就不需要添加标签。)
python代码
import numpy as n...
根据样本
点距初始聚类
点的距离,将样本
点分类。样本
点距离那个初始聚类
点最近就分为哪一类,随机初始聚类
点(k个),并计算分类后各簇的均值。
数据下载链接:
链接:https://pan.baidu.com/s/1GT2HGMRtYJsVm7iWMi4qRw
提取码:up6x
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat
mat = loadmat("./data/ex7data2.mat")
参考网站:https://www.python-course.eu/dividing_lines_between_classes.php
上一节我们可以自动的识别出能够将两个点分开的直线簇,但是我们的目标不是将两个点分开,而是两类点,本节我们就尝试一下由这两个点生成两类点簇,为后续分类做准备。
import numpy as np
import matplotlib.pyplot as plt
[4,5],[5,6],[6,7],[7,4],
[0,4],[1,5],[2,6],[3,7]]
bbox_colors = [[1,0,0] for i in range(len(bbox_lines))]
line_set = o3d.geometry.LineSet(
points=o3d.utility.Vector3dVector(bbox_points),
lines=o3d.utility.Vector2iVector(bbox_lines),
line_set.colors = o3d.utility.Vector3dVector(bbox_colors)
vis.add_geometry(line_set)
# 使用DBSCAN算法进行聚类
labels = np.zeros(points.shape[0])
eps = 0.1
min_points = 10
for i in range(points.shape[0]):
if labels[i] != 0:
continue
neighbors = np.where(np.sum((points - points[i])**2, axis=1) < eps**2)[0]
if neighbors.shape[0] < min_points:
labels[i] = -1
else:
labels[neighbors] = i+1
# 将聚类结果可视化,并将不同的聚类用不同的颜色显示
cluster_colors = [[np.random.uniform(0, 1), np.random.uniform(0, 1), np.random.uniform(0, 1)] for i in range(np.max(labels))]
for i in range(np.max(labels)):
if i == -1:
continue
cluster_points = points[labels==i,:]
cluster_pcd = o3d.geometry.PointCloud()
cluster_pcd.points = o3d.utility.Vector3dVector(cluster_points)
cluster_pcd.paint_uniform_color(cluster_colors[i])
vis.add_geometry(cluster_pcd)
# 显示可视化窗口
vis.run()
vis.destroy_window()
这个示例代码使用了Open3D库进行点云数据的读取、转换、可视化和聚类,其中DBSCAN算法用于聚类。在可视化过程中,将点云数据用绿色显示,将三维包围盒用红色显示,将不同的聚类用不同的随机颜色显示。
### 回答2:
在使用Python生成代码进行pcd雷达点云数据障碍物识别并进行可视化及标出障碍物的过程中,可以使用一些常用的第三方库来实现。
首先,我们需要加载pcd雷达点云数据。可以使用open3d库中的read_point_cloud函数来加载pcd文件,并将其转换为numpy数组。
接着,我们可以使用一些机器学习算法来对点云数据进行障碍物的识别。例如,可以使用scikit-learn库中的聚类算法,如DBSCAN或K-Means来对点云数据进行聚类。聚类的结果可以用于区分障碍物和背景。
然后,我们可以通过将识别出的障碍物点云数据与原始点云数据进行可视化来标出障碍物。可以使用open3d库中的可视化功能,通过创建一个PointCloud对象并设置点云的颜色来实现。
最后,我们可以将带有标注障碍物的可视化结果保存为新的pcd文件。使用open3d库的write_point_cloud函数,将带有标注信息的点云数据保存为pcd格式的文件。
综上所述,使用Python生成代码进行pcd雷达点云数据障碍物识别、可视化并标出障碍物的整个流程可以通过这些步骤完成。通过逐步调试和优化,可以实现更准确、高效的障碍物识别和可视化。
### 回答3:
使用Python进行pcd雷达点云数据障碍物识别并可视化并标出障碍物,可以按照以下步骤进行:
1. 导入必要的库:在Python中,可以使用numpy库来处理点云数据,使用open3d库进行点云的可视化和处理。
2. 读取pcd文件:使用open3d库中的`read_point_cloud`函数来读取pcd文件,并将其存储为点云对象。
3. 预处理点云数据:可以根据需要进行点云数据的预处理,例如去除离群点、滤波等操作,以增加障碍物识别的准确性。
4. 障碍物识别:可以使用各种机器学习或深度学习算法来进行障碍物识别。例如,可以使用聚类算法,如DBSCAN、MeanShift等,将点云数据聚类成不同的障碍物。还可以使用深度学习模型,如卷积神经网络(CNN)或点云处理网络(PointNet)等来进行障碍物的检测和分类。
5. 可视化并标出障碍物:使用open3d库的可视化功能将处理后的点云数据进行可视化,并通过不同的颜色或其他标记来标出障碍物。可以使用open3d库中的`draw_geometries`函数将点云对象显示出来,然后使用不同的颜色或标记来区分识别出的障碍物和其他点。
6. 输出结果:可以将可视化后的结果保存为图片或视频,以便后续分析和展示。
总结:使用Python进行pcd雷达点云数据障碍物识别可以通过导入必要库、读取pcd文件、预处理数据、障碍物识别、可视化并标出障碍物等步骤完成。这个过程可以根据具体需求进行调整和拓展,以满足不同的应用场景。