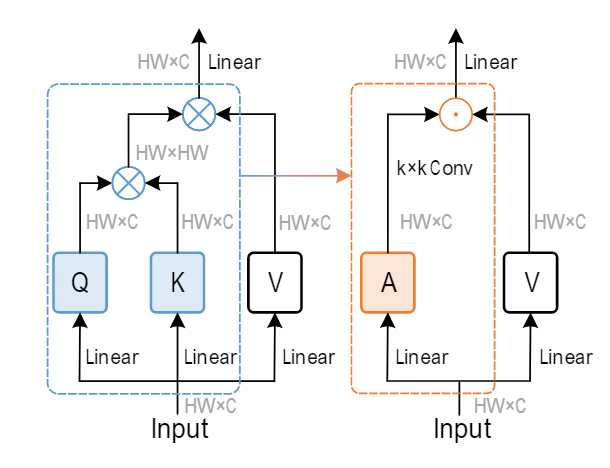
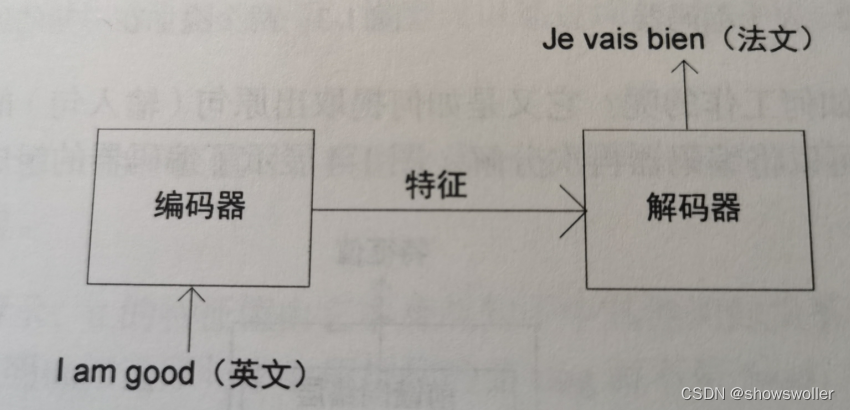
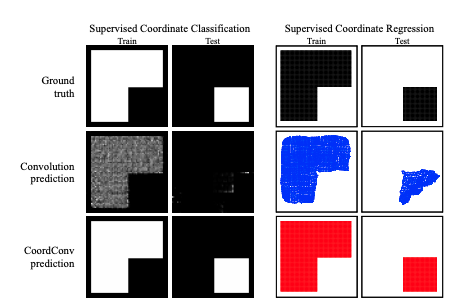
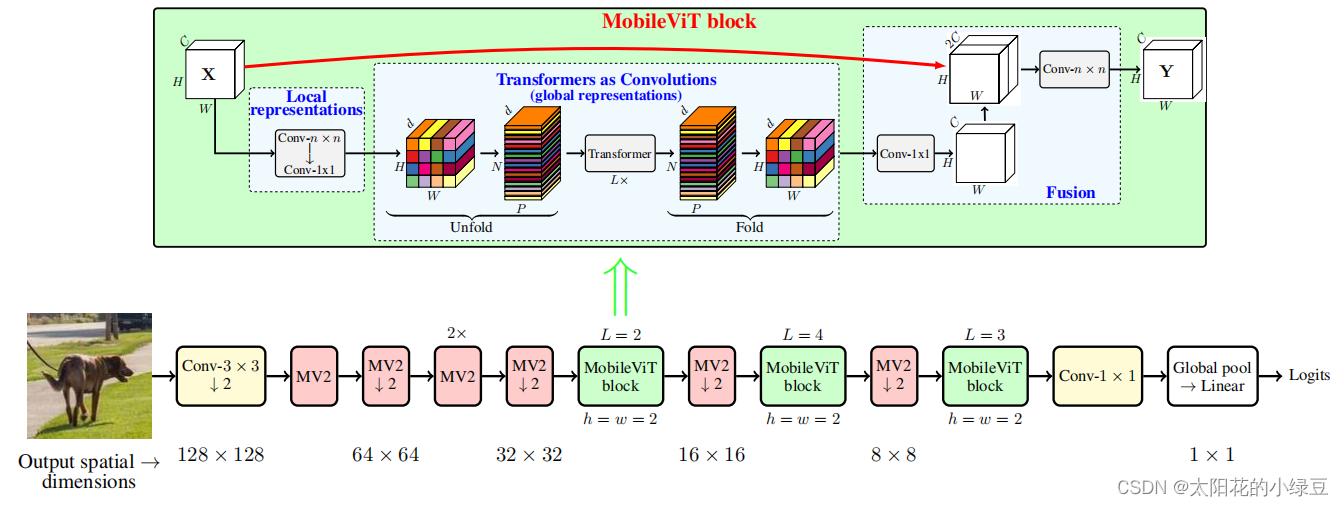
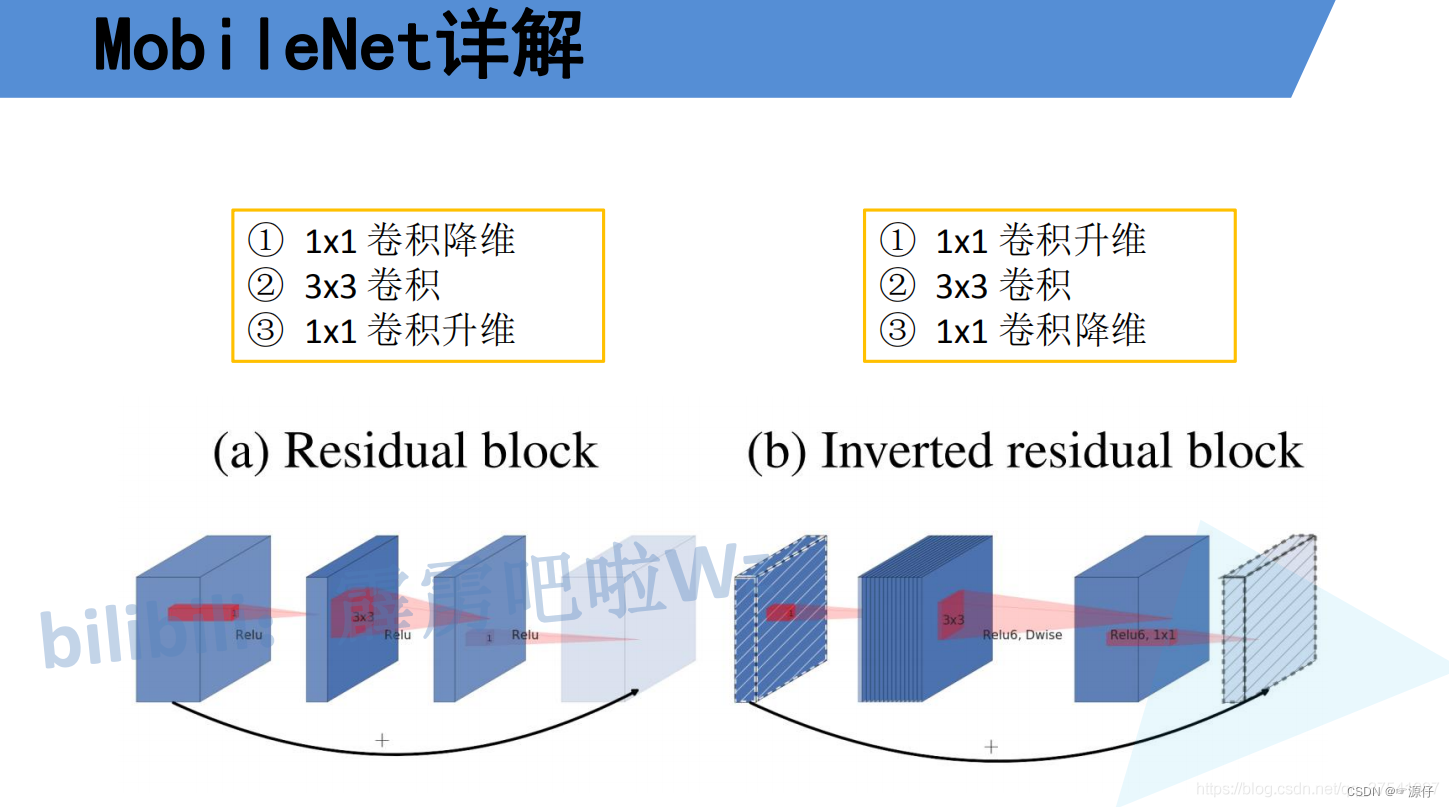
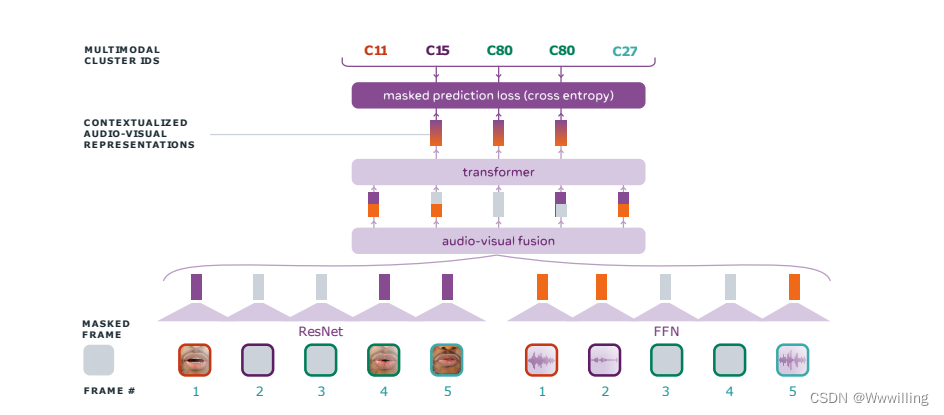
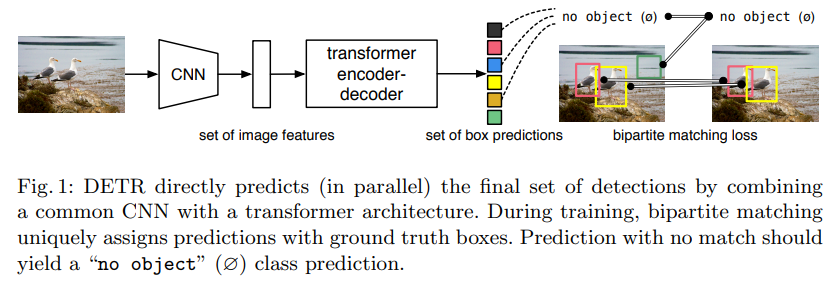
transformer
-
-
一个热爱学习的深度渣渣
 松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2022-01-28 15:29:36
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2022-01-28 15:29:36
-
百态老人
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-02-13 11:35:35
-
kaiyuan_sjtu
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-02-25 11:05:33
-
showswoller
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-03-23 22:09:08
-
这是个大号
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-03-24 11:06:01
-
Chaos_Wang_
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-03-16 23:35:05
-
AbnerAI
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-02-15 15:57:11
-
szd小灰灰
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-03-23 17:08:27
-
皮皮要HAPPY
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-03-14 12:41:16
-
PaperWeekly
松山湖开发者村综合服务平台
songshanhu.csdn.net
· 2023-02-25 20:36:58
-
C学堂
 科技大事业开发者社区
devpress.csdn.net/developer
· 2023-04-10 15:53:23
科技大事业开发者社区
devpress.csdn.net/developer
· 2023-04-10 15:53:23
-
Conda的编程杂货铺
 AIGC开发者社区
devpress.csdn.net/aigc
· 2023-02-25 10:56:27
AIGC开发者社区
devpress.csdn.net/aigc
· 2023-02-25 10:56:27
-
育种数据分析之放飞自我
AIGC开发者社区
devpress.csdn.net/aigc
· 2023-02-14 21:07:23
-

华为云开发者联盟
 华为云开发者联盟
huaweicloud.csdn.net
· 2023-03-28 10:22:01
华为云开发者联盟
huaweicloud.csdn.net
· 2023-03-28 10:22:01
-
太阳花的小绿豆
 开源项目管理
devpress.csdn.net/gitcode
· 2022-09-05 23:43:49
开源项目管理
devpress.csdn.net/gitcode
· 2022-09-05 23:43:49
-
☞源仔
开源项目管理
devpress.csdn.net/gitcode
· 2022-05-26 11:20:17
-
athrunsunny
开源项目管理
devpress.csdn.net/gitcode
· 2022-05-23 23:58:54
-
九筒-
开源项目管理
devpress.csdn.net/gitcode
· 2022-05-04 19:45:03
-
得克特
开源项目管理
devpress.csdn.net/gitcode
· 2019-09-11 16:37:34
-
MayMayWang
开源项目管理
devpress.csdn.net/gitcode
· 2022-04-12 13:02:08
-
热血厨师长
开源项目管理
devpress.csdn.net/gitcode
· 2022-01-24 14:46:33
-

是七叔呀
开源项目管理
devpress.csdn.net/gitcode
· 2022-05-04 11:26:05
-
拟禾
华为云开发者联盟
huaweicloud.csdn.net
· 2023-02-24 19:53:00
-

智慧地球 AI·Earth
 智慧地球 AI·Earth
devpress.csdn.net/aiearth
· 2023-01-15 21:39:50
智慧地球 AI·Earth
devpress.csdn.net/aiearth
· 2023-01-15 21:39:50
-
IE06
 ModelScope魔搭社区
community.modelscope.cn
· 2022-06-10 15:03:20
ModelScope魔搭社区
community.modelscope.cn
· 2022-06-10 15:03:20
-
Wwwilling
ModelScope魔搭社区
community.modelscope.cn
· 2022-10-26 23:07:13
-
SunnyGJing
ModelScope魔搭社区
community.modelscope.cn
· 2022-04-17 22:37:00
-
我已经吃饱了
ModelScope魔搭社区
community.modelscope.cn
· 2022-03-18 14:19:25
-
BQW_
ModelScope魔搭社区
community.modelscope.cn
· 2022-02-08 22:38:49
-
AI Studio
 百度飞桨AI Studio社区
aistudio.csdn.net
· 2022-12-28 23:14:35
百度飞桨AI Studio社区
aistudio.csdn.net
· 2022-12-28 23:14:35
-
木卯_THU
华为云开发者联盟
huaweicloud.csdn.net
· 2021-09-26 19:59:43
-
ydmy
华为云开发者联盟
huaweicloud.csdn.net
· 2022-03-24 17:47:02
-
华为云开发者联盟
华为云开发者联盟
huaweicloud.csdn.net
· 2022-12-23 15:59:23
-
AI Studio
百度飞桨AI Studio社区
aistudio.csdn.net
· 2022-11-27 21:47:03