


TFIDF+Wordembedding无监督多标签文本分类算法(论文解读)


论文名称:Improving Recall and Precision in Unsupervised Multi-Label Document Classifification Tasks by Combining Word Embeddings with TF-IDF
一、现有的关键字提取技术
TFIDF, 统计学方法
TF:单词的重要性随着它在文本中出现的次数成正比增加,也就是单词的出现次数越多, 该单词对于文本的重要性就越高。
IDF:同时单词的重要性会随着在语料库中出现的频率成反比下降,也就是单词在语料库 中出现的频率越高,表示该单词越常见,也就是该单词对于文本的重要性越低
TF-IDF的优点是简单快速,而且容易理解
缺点: 首先,TFIDF在对单个文档时无法起作用,如果没有整个语料集,其次缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性
TextRank算法
原本是用于文本摘要生成,现在也可以用于提取关键字,关键字提取任务时,TextRank比TFIDF效果要好,但是缺点是有时会忽略文本中出现次数很少,但是很重要的词
主题模型LDA
主题模型(Topic Model)是用来在一系列文档中发现抽象主题的一种统计模型。直观来 讲,如果一篇文章有一个中心思想,那么一定存在一些特定词语会出现的比较>频繁。比 方说,如果现在一篇文章是在讲苹果公司的,那么“乔布斯”和“IPhone”等词语出现 的频率会更高一些
LDA主题模型最大的问题是,它们提取出来的关键字集合的主题很难解释
以上3种方法都是利用了BOW法,但是词袋法的向量非常稀疏,如果文本中有拼写错误,同义词,或者单词变形等,都会让向量更加稀疏,常用的处理方法是词干法,词性转换,拼写检查,同义词替换,但是最根本的问题还是没有抓住语义信息。
分布式表示的方法(词向量的方法)分类
分布式表示法基本上依赖于word2vec,例如sentence vector,phrase vector,document vect,
基于分布式表示法的分类的缺点就是需要大量人工去给文档标注类别,其次这种标签还经常需要再次标注当单词表发生改变,最后是word2vec和分离器都需要定期的训练
混合分类方法
Verma和Arora(2017)提出了一种混合方法来动态匹配消费者的问题的最相似的问题。他们使用余弦相似度将word2vec,tf-idf和tf-idf与部分词性标记集成在一起进行计算。研究表明,混合方法优于单独方法, Arora et al. 2017年使用词向量的平均值代表句子向量,然后使用PCA和SVD分解进行计算。 Wang et al. (2016)提出了结合word2vec和LDA的特征文档提取的方法, 生成的文档向量考虑了文档之间的关系和主题,以及单词之间的关系, Yilmaz et al. (2017)提出了word2vec结合KNN的一种方法, Tae et al. (2006) 提出SVM结合KNN的一种方法,Tae et al. (2006) 提出一种hypersphere-SVM结合k-congener-nearest-neighbors-SVM处理数据的不平衡问题,Kumar and Ravi (2018)提出主题模型结合Class Association Rule Mining (CARM)模型的方法, Nam and Quoc (2015)提出频率方法结合聚类方法。
Tiwari and Singh (2015)使用排序算法ranking method (RelieF),Gao et al. (2008) 提出决策树结合神经网络的方法
二 本论文中使用的方法
document-tag- cosine similarity (dt-cs) 和 tf-idf 结合的方法。
Document-tag-cosine-similarity (dt-cs), 文档标签余弦相似度,是一种将关键字分配给文档的无监督的方法, 它使用的是word2vec和paragraph2vec训练词向量和文档向量,然后将词向量转出成关键字向量,最后文档向量和关键字向量都变成同一结构和维度, 最后计算每个文档和关键字的向量之间的余弦相似度
补充方法分析
本论文的主要策略是寻找2个互补的方法,鉴于有数十种可以组合的方法,本论文不能找出哪种组合是最好的,只是分析出哪种是最适合的针对每种方法的强项和弱点。本文从词向量开始研究,因为近些年来,词向量证明了有很好的效果,例如Embeddings from Language Models (ELMo) (Peters et al., 2018), Bidirectional Encoder Represen- tations from Transformers (BERT) (Devlin, Chang, Lee and Toutanova, 2018), and Robustly Optimized BERT Pretraining Approach (RoBERTa) (Liu et al., 2019), 对于这个任务,我们需要的是词向量和文档向量,对于Bert而言获取句子或者段落向量的方法是平均所有词向量或者使用bert的CLS token,然后这个句子或段落向量在计算余弦相似度时被证明效果是比较差的,甚至比Global Vectors for Word Representation (GloVe) (Pennington, Socher and Manning, 2014) 还要差, 现在还没有证据表明通过平均词向量得到的文档向量是有效的,这也是paragraph2vec (Le and Mikolov, 2014), 也叫doc2vec发展的动机。而且Bert有512个token的限制,不能表示全部的长文本,而基于doc2vec的文档向量表示法被证明是有效的,这也是我们选择dt-cs的原因。
三 理论分析
TFIDF的优点和缺点
Tf-idf因其易于实现而闻名,因为该方法基于简单的统计信息。tf-idf提供的关键字肯定会出现在文档中,并且top关键字通常能够较好的描述该文档。但是,选取单个经常出现的关键字可能不太适合作为文档的特征,虽然它出现频率较高,但不能代表主要话题。例如某些停用词,这一点尤其明显如果在预处理期间未过滤掉。
同义词:TFIDF不能处理同义词,甚至同一个词的不同的变形也不可以处理,例如run和ran,所以需要词干或词根法处理
多意词:TFIDF无法处理一个单词有多个意思的情况
False positives: 把坏的预测为好的的情况,从纯粹的统计学角度来看,由于每个单词都在文档中至少出现一次,因为没有所谓的FP, 但是从分类角度看, 如果这个关键字不能描述这个文档,那么这个就是FP
False negatives: 把好的预测为坏的情况,TFIDF可能存在丢失关键字的情况,例如一篇描述政治的文章,但是通篇没有政治这个关键字,或者这个关键字出现次数很少,所以这个字就不太可能在top k个关键字中,但是如果这个词很重要,这就出现了FN
人为设置的关键字集合: 如果人为给定关键字集合,那么TFIDF只需要允许出现给定关键字集合中出现的单词,但是大量的关键字可能会丢失,例如TFIDF筛选出laptop,但是给定的词集合是notebook,为了解决这个问题,需要使用进一步的匹配算法,或者使用映射表将laptop映射到notebook
dt-cs的优点和缺点
分布式表示法的强项是词向量和文档向量能够包含这些文档的上下文, 这样就会更健壮,这样词向量虽然未出现在文档中,但却可以表达文档中的意思
同义词:因为文字是结合上下文表示的,所以dt-cs可以理解同义词,同义词的余弦相似度也越高
多意词:dt-cs也不能区别多义词
False positives: dt-cs很可能会出现FP当单词有相似的上下文环境时,假如“cats,” “dogs,” 和 “pets” 都用相似的上下文表达,”dog“这个词可能错误的分给描述猫的文档,FP问题可以通过更大量的语料库训练解决,因此dt-cs给文档分类就像一个小球射击游戏,它会击中一些相近的单词,其中这些单词有正确的也有错误的。
False negatives:dt-cs也可能产生FN,因为相关的单词可能和给定的文档的余弦相似度很低,
人为设置的关键字集合:因为dt-cs能很好的处理同义词,所以这个dt-cs能够解决这个匹配问题。
基于以上分析,我们认为TF-IDF和dt-cs有相反的特性。以下是进行证实
证实TF-IDF和DT-CS的特性
如下是对一份样本集进行计算关键字,分别使用TF-IDF和DT-CS,结果如图表示,手动分配的标签仅仅作为参考
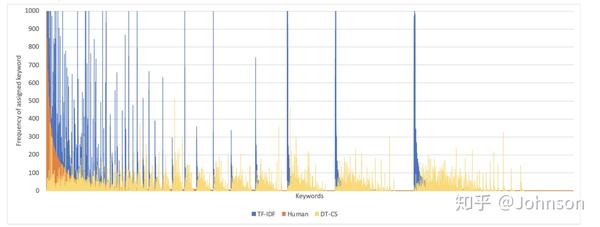
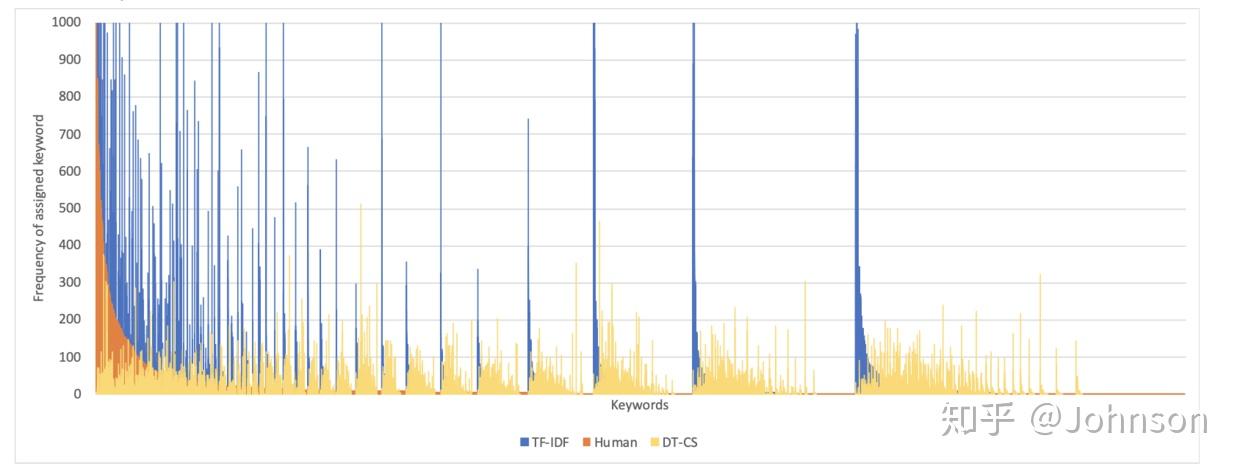
上图X轴是大约10000个关键字,Y轴是出现的频率,图中橘色部分是人工标记的标签,就是最左侧的,显示出非常的不平衡的数据,这些频率大概在50到800之间,很少出现50以下的情况,蓝色的线是TFIDF的标签分布,黄色的是DT-CS的标签分布,这个图不是显示哪种方法更准确,只是证明了TFIDF和DT-CS的特性是有很大区别,事实上,TFIDF的前10%的单词占据了77%的标签,而dt-cs只是59%,显然dt-cs的比TFIDF更分散.
四 无监督文本分类的组合方法实现过程
给定需要标记文档的一组有限关键字, 这是一个分类任务。通常分类是指有监督的任务,首先需要在标记好的训练数据上训练模型,然后使用训练后的模型去给新的文件分类。但是,这里分类是用于无监督方法,将一些标签分配给文档。定义如下:
uDocs: 需要标记的未标记文档。
finTags: 应分配给uDocs的预先定义的关键字集合。最重要的一点是,不需要标记的训练数据, 我们的方法包括四个步骤:
第一步(representation:计算uDocs所有单词的tf-idf表示形式。另外,建立单词和文档的向量通过Paragraph Vector Distributed Memory (PV-DM) approach of Le and Mikolov (2014)
第二步(filter):过滤掉未包含在finTags中的所有tf-idf单词和dt-cs表示的单词,但是保留所有向量文档向量。
第三步(top keywords):确定两种方法的top keywords。对于tf-idf,对tf-idf计算的得到的关键字进行排序,要确定dt-cs的top keywords,通过计算文档向量和单词向量之间的余弦相似度,以找到最佳匹配。对于每个文档,我们计算与所有单词向量的余弦相似度,并按最高的余弦相似度排序,如下图, 最后,我们获得了tf-idf和dt-cs的top匹配。
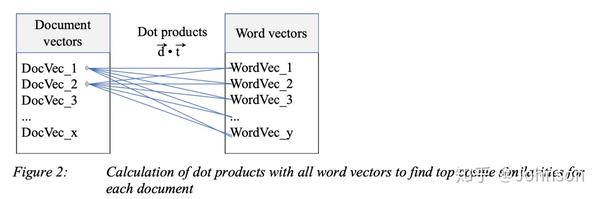
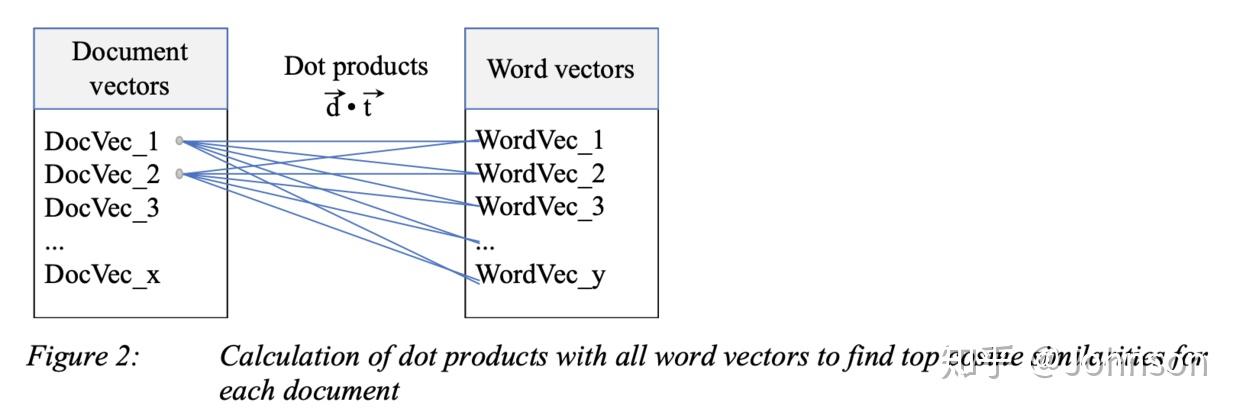
第四步(unite results):统一结果,通过采用两种方法结果前n / 2个关键字组合的方式作为结果。
如下图展示的整个流程:
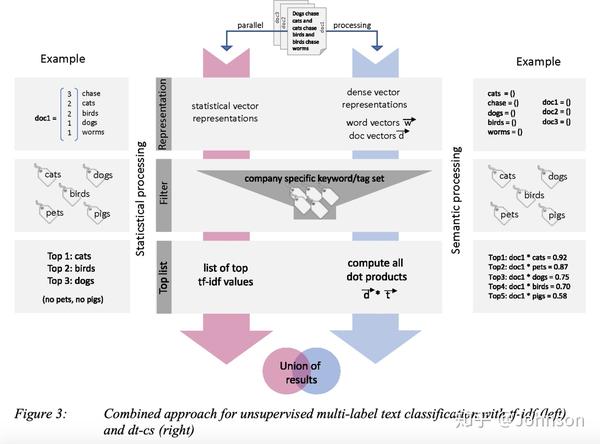
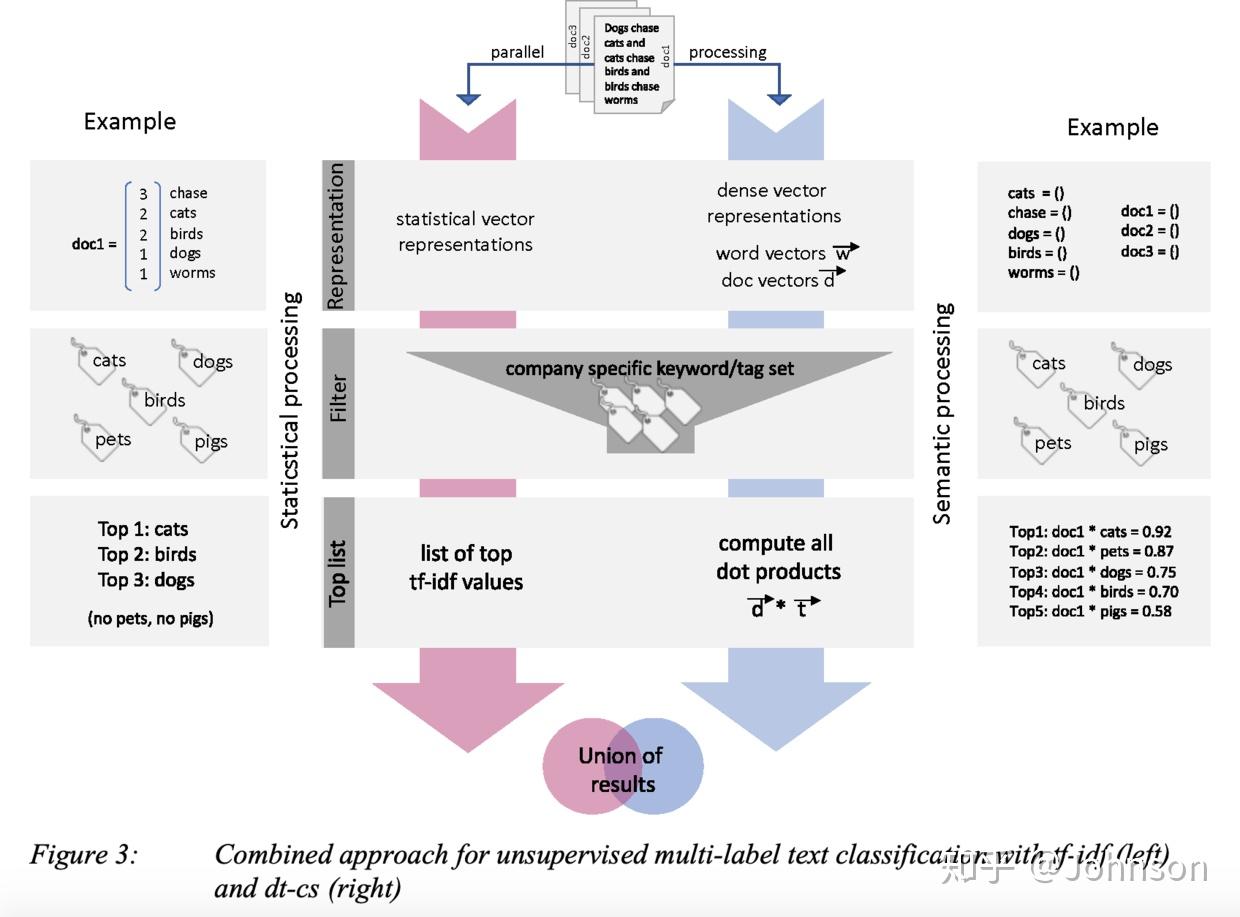
五 评估
数据集评估采用的是德国一家广播公司的手稿,大约 63165份,共计7000万个字,共有9885个关键字组成关键字集合,一共7158个关键字标注了63165分文档。
评估结果:
用的是sklean计算tf-idf,词向量是用的gensim初始化,然后在做dt-cs之前,进行了大写转换成小写,数字转换,例如9变成nine,移除所有特殊字符和音标,去除了停止词。
共计算63165*9885次与余弦相似度,筛选出能代表文档的最好的余弦相似度的单词。做了这些操作后,我们发现召回率和精确率逗比单独的tf-idf和dt-cs要地一些,这是由于我们数据集的特性的关系。对于对比标记好的tag,我们发现tf-idf的效果要好于dt-cs,为了进行对比我们还使用了bert模型。
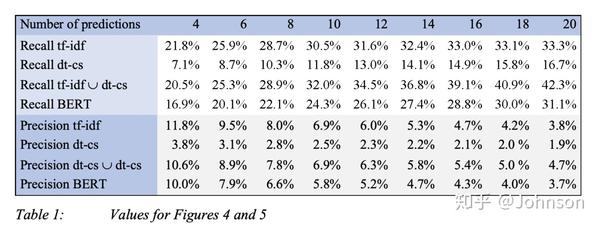
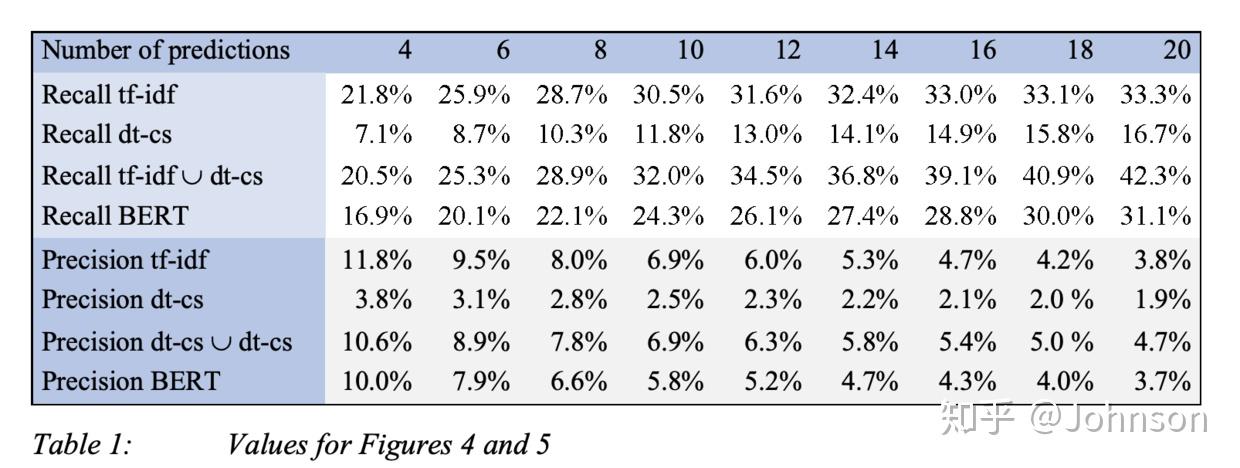
召回率:对于超过8个关键字的预测,我们的组合方法会好于任何单一的方法, Bert效果不太好的原因是没有足够的标记好的训练集,是有监督的,而我们是无监督的,这也是我们这次实验的初衷。
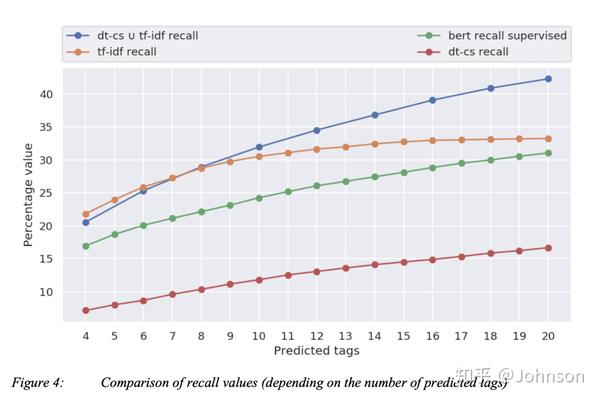
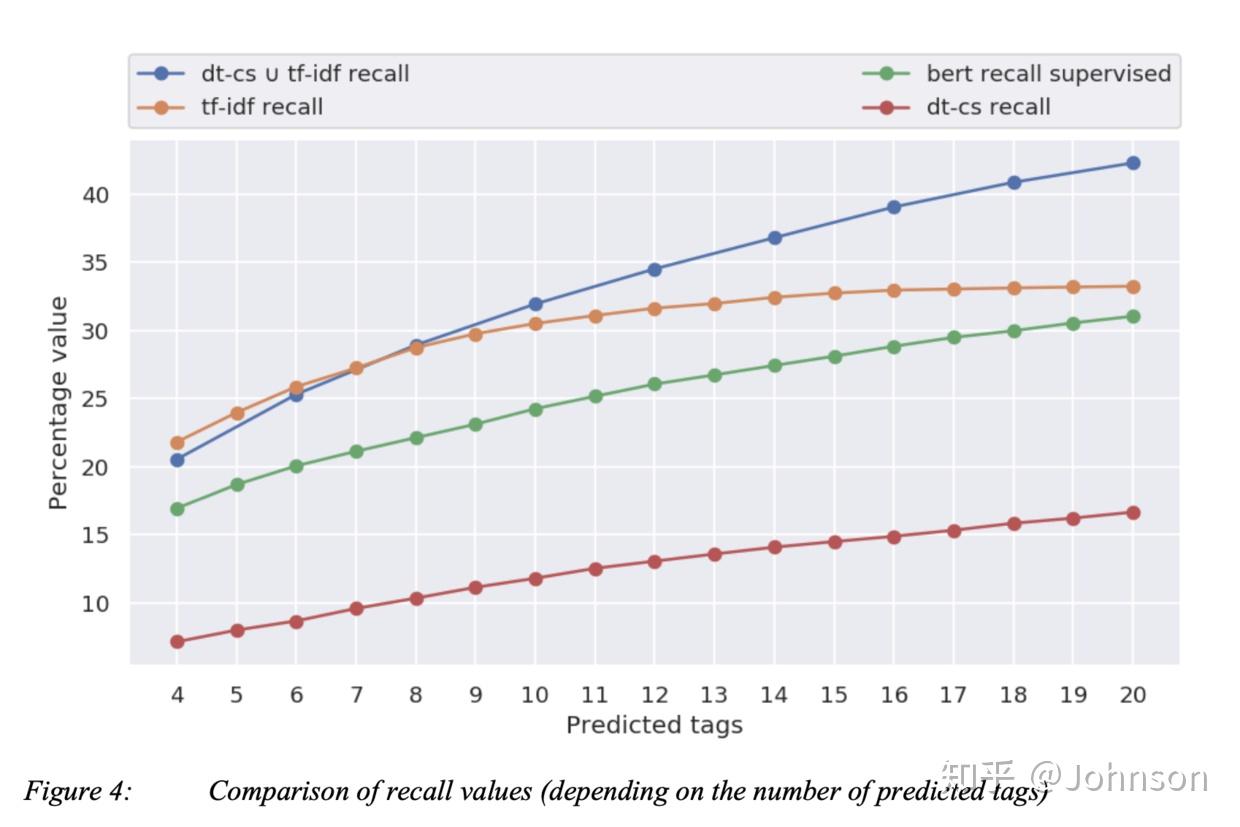
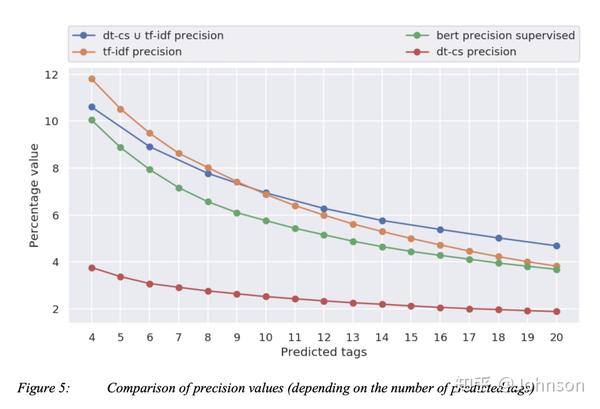
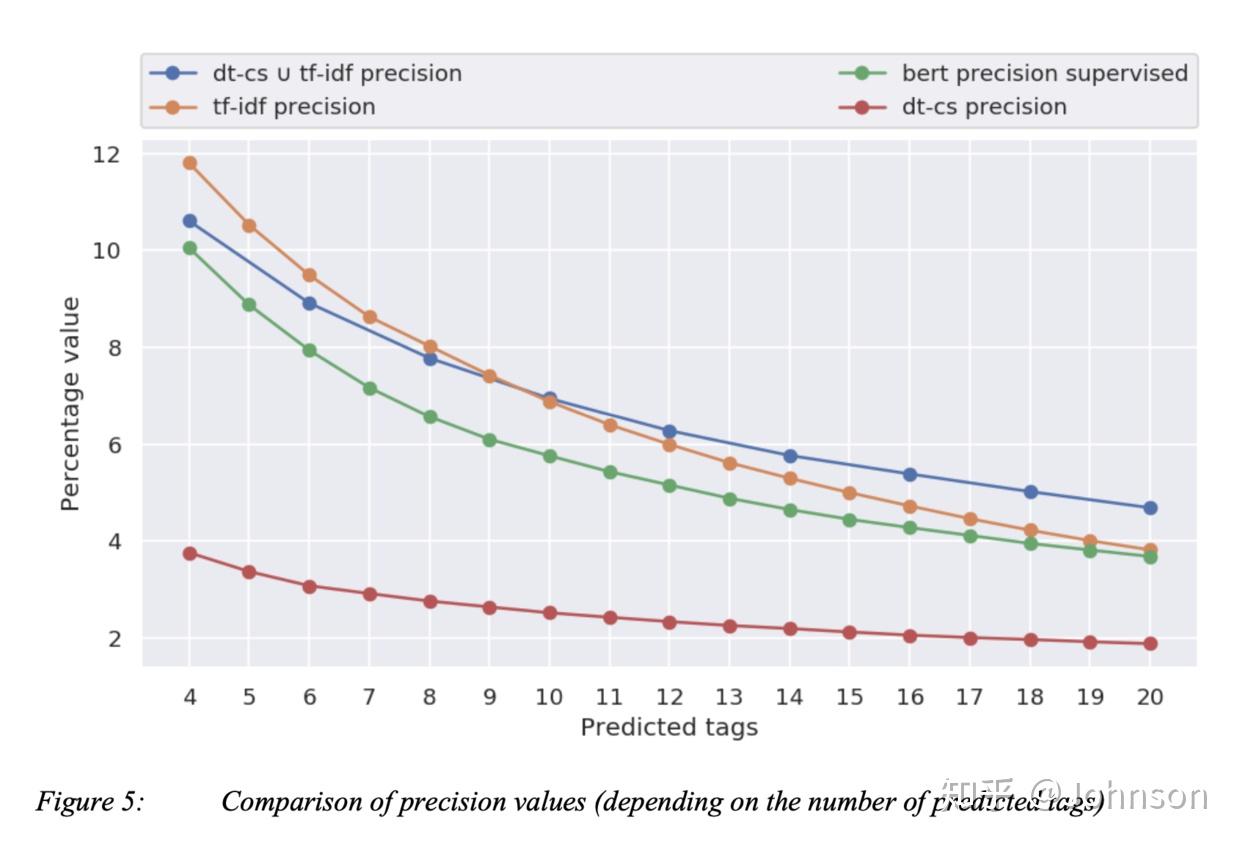
精确率: 对于超过9个关键的预测,组合方法会好于任何单一的方法
六 总结:
我们为多标签文档分类提供了一种无监督的方法,结合两种具有互补优势的方法,表明这种结合可以显着可以在不降低精确率的情况下提高召回率。我们还阐明了dt-cs和tf-idf的互补优势,并系统通过此方法予以启发其它更富有成效的组合方法。
在组合方法实践的相关性时,我们给出一个人机协作的方案。机器先几千个关键字中选出最可能的20个关键字,人只需要从20个关键字选出最可能的那些即可, 当需要确定尽可能多的关键字是,我们的组合方法可以提高召回率,而无需失去甚至略有提高的精确率。机器预测的召回率越高, 人们得到的结果越好。
我们也尝试通过建立tf-idf和dt-cs结果的交集来提高精度, 然而,由于交集经常是空的或仅包含一个或两个关键字,因此我们无法获取有意义的结果。但是,这再次表明了我们的方法的互补优势。
我们的组合方法有一些局限性。首先,对于小数量的关键字预测,该方法是不适合的,其次,关键字组合受每个方法可以提供的关键字的数量限制。最后,由于两种方法都无法应对多义词。
虽然在本文中使用了tf-idf,但我们认为这种方法或三种方法的组合可能会进一步提高召回率和精确率。