


《SQL编程思想》第3章 逻辑处理功能

本章我们将会学习常用的SQL函数,同时还会了解如何利用条件表达式为SQL语句增加逻辑处理功能。
本章涉及的主要知识点包括:
- 常用数值函数。
- 常用字符函数。
- 常用日期函数。
- 类型转换函数。
- 条件表达式(CASE)。
3.1 函数和运算
SQL主要的功能就是对数据进行处理和分析。为了提高数据处理的效率,SQL为我们提供了许多预定义的功能模块,也就是函数(Function)。
3.1.1 函数概述
SQL函数是一种具有某种数据处理功能的模块,它可以接收零个或多个输入值,并且返回一个输出值。SQL中的函数主要分为以下两种类型:
- 标量函数(Scalar Function),针对每个输入参数返回一个输出结果。例如ABS(x)函数可以计算x的绝对值。
- 聚合函数(Aggregate Function),基于一组输入参数进行汇总并返回一个结果。例如AVG(x)函数可以计算一组数据的平均值。
本章只涉及SQL标量函数,聚合函数将会在下一章进行介绍。为了方便学习,我们可以将常见的SQL标量函数分为以下几类:数值函数、字符函数、日期函数以及类型转换函数。
3.1.2 数值函数
数值函数通常接收一个或者多个数字类型的参数,并且返回一个数值结果。表3.1列出了常见的SQL数值函数及它们在5种主流数据库中的实现。
表3.1 常见SQL数值函数与实现
| 数值函数 | 函数功能 | Oracle | MySQL | Microsoft SQL Server | PostgreSQL | SQLite |
| ABS(x) | 计算x的绝对值 | 支持 | 支持 | 支持 | 支持 | 支持 |
| CEIL(x)、CEILING(x) | 返回大于等于x的最小整数 | CEIL(x) | 支持 | CEILING(x) | 支持 | CEIL(x) |
| FLOOR(x) | 返回小于等于x的最大整数 | 支持 | 支持 | 支持 | 支持 | 支持 |
| MOD(x, y) | 计算x除以y的余数 | 支持 | 支持 | x % y | 支持 | x % y |
| ROUND(x, n) | 将x四舍五入到n位小数 | 支持 | 支持 | 支持 | 支持 | 支持 |
| RANDOM() | 返回一个伪随机数 | DBMS_RANDOM | RAND() | RAND() | 支持 | RANDOM() |
注意:SQLite 3.35.0开始支持内置的数值函数,不再需要单独编译extension-functions.c文件,使用方法请参考官方文档。
下面我们通过一些示例来说明这些函数的作用和注意事项。
1. 绝对值函数
ABS(x)函数计算输入参数的绝对值,例如:
SELECT ABS(-1), ABS(1), ABS(0)
FROM employee
WHERE emp_id = 1;我们借助employee演示各种函数的作用,读者也可以使用第1章中介绍的快速查询语句。查询返回的结果如下。
ABS(-1)|ABS(1)|ABS(0)
-------|------|------
1| 1| 02. 取整函数
CEIL(x)和CEILING(x)函数返回大于等于x的最小整数,也就是向上取整。FLOOR(x)函数返回小于等于x的最大整数,也就是向下取整。例如:
SELECT CEIL(-2), CEILING(-2), FLOOR(4.5)
FROM employee
WHERE emp_id = 1;Oracle不支持CEILING(x)函数,Microsoft SQL Server不支持CEIL(x)函数。查询返回的结果如下。
CEIL(-2
)|CEILING(-2)|FLOOR(4.5)
--------|-----------|----------
-2| -2| 4ROUND(x, n)函数将x四舍五入到n位小数,也就是执行四舍五入运算。例如:
SELECT ROUND(9.456, 1), ROUND(9.456)
FROM employee
WHERE emp_id = 1;第二个函数调用时省略了参数n,表示四舍五入到整数。Microsoft SQL Server不能省略参数n,可以将ROUND(9.456)替换成ROUND(9.456, 0)。查询返回的结果如下。
ROUND(9.456, 1)|ROUND(9.456)
---------------|------------
9.5| 93. 求余函数
MOD(x, y)函数计算x除以y的余数,也就是执行求模运算。例如:
-- Oracle、MySQL以及PostgreSQL
SELECT MOD(5,3)
FROM employee
WHERE emp_id = 1;Oracle、MySQL以及PostgreSQL实现了MOD函数。查询返回的结果如下。
MOD(5,3)
--------
2Microsoft SQL Server和SQLite没有提供MOD函数,可以使用%运算符进行求模运算:
-- Microsoft SQL Server、MySQL、PostgreSQL以及SQLite
SELECT 5 % 3
FROM employee
WHERE emp_id = 1;MySQL和PostgreSQL也支持这种语法。查询返回的结果和上面的示例相同。
4. 生成伪随机数
通过计算机生成的随机数都是伪随机数,数据库都提供了生成伪随机数的函数。
MySQL使用RAND函数返回一个大于等于0小于1的随机数。Microsoft SQL Server也使用RAND函数返回随机数,但是随机数的取值范围为大于0小于1。例如:
-- MySQL和Microsoft SQL Server
SELECT RAND()
FROM employee
WHERE emp_id <= 3;对于MySQL而言,在一个查询语句中的多次RAND函数调用都会返回不同的随机数。查询返回的结果如下。
RAND()
-------------------
0.12597889371773124
0.6288336549222783
0.7662316241918427对于Microsoft SQL Server,在一个查询语句中的多次RAND函数调用返回相同的随机数。查询返回的结果如下。
RAND()
-------------------
0.47224141500963573
0.47224141500963573
0.47224141500963573正常情况下,如果你运行上面的示例将会得到的不同随机数。不过,我们也可以为RAND函数指定一个随机数种子,重现相同的随机数。例如:
-- MySQL和Microsoft SQL Server
SELECT RAND(1);其中,函数中的参数1是随机数种子。多次执行以上查询将会返回相同的结果。
Oracle提供了一个系统程序包DBMS_RANDOM,其中的VALUE函数可以用于返回大于等于0小于1的随机数。例如:
-- Oracle
SELECT DBMS_RANDOM.VALUE
FROM employee
WHERE emp_id <= 3;查询返回的结果如下。
VALUE
----------------------------------------
0.18048925385153716390255039523196767411
0.3353631757935088547857071602303392595
0.3412188906823928592522036537134902456对于Oracle,每次调用RAND函数都会返回不同的随机数。
提示:Oracle系统程序包DBMS_RANDOM中还提供了其他生成随机数和随机字符串的函数,以及设置随机数种子的方法,可以查看官方文档。
PostgreSQL提供了RANDOM函数,可以返回一个大于等于0小于1的随机数。例如:
-- PostgreSQL
SELECT RANDOM()
FROM employee
WHERE emp_id <= 3;查询返回的结果如下。
random
------------------
0.1523788485137807
0.2580784959938427
0.0528612944722024对于PostgreSQL,每次调用RANDOM函数都会返回不同的随机数。如果想要重现相同的随机数,可以使用SETSEED函数。例如,重复执行以下两个语句可以得到相同的随机数:
-- PostgreSQL
SELECT SETSEED(0);
SELECT RANDOM();SQLite也提供了RANDOM函数,可以返回一个大于等于-263小于等于263-1的随机整数。例如:
-- SQLite
SELECT RANDOM()
FROM employee
WHERE emp_id <= 3;查询返回的结果如下。
RANDOM()
--------------------
3344080139226703236
-4444734262945592004
8384000175497818543对于SQLite,每次调用RANDOM函数都会返回不同的随机数。SQLite不支持随机数种子设置,无法重现相同的随机数。
提示:除了我们上面介绍的函数之外,SQL还提供其他的数值函数,例如乘方和开方函数、对数函数以及三角函数,有需要时可以查看数据库相关的文档。
3.1.3 字符函数
字符函数用于字符数据的处理,例如字符串的拼接、大小写转换、子串的查找和替换等。表3.2列出了常见的SQL字符函数及它们在5种主流数据库中的实现。
表3.2 常见SQL字符函数与实现
| 字符函数 | 函数功能 | Oracle | MySQL | MicrosoftSQL Server | PostgreSQL | SQLite |
|---|---|---|---|---|---|---|
| CHAR_LENGTH(s) | 返回字符串s包含的个数 | LENGTH(s) | 支持 | LEN(s) | 支持 | LENGTH(s) |
| 字符函数 | 函数功能 | Oracle | MySQL | MicrosoftSQL Server | PostgreSQL | SQLite |
|---|---|---|---|---|---|---|
| CONCAT(s1, s2, …) | 连接字符串 | 支持 | 支持 | 支持 | 支持 | || |
| INSTR(s, s1) | 返回子串首次出现的位置 | 支持 | 支持 | PATINDEX(s1, s) | POSITION(s1 IN s) | 支持 |
| LOWER(s) | 返回字符串s的小写形式 | 支持 | 支持 | 支持 | 支持 | 支持 |
下面我们通过一些示例来说明这些函数的作用和注意事项。
1. 字符串长度
字符串的长度可以按照两种方式进行计算:字符数量和字节数量。在多字节编码中,一个字符可能占用多个字节。
CHAR_LENGTH(s)函数用于计算字符串中的字符数量,OCTET_LENGTH(s)函数用于计算字符串包含的字节数量。例如:
-- MySQL和PostgreSQL
SELECT CHAR_LENGTH('数据库'), OCTET_LENGTH('数据库');查询返回的结果如下。
CHAR_LENGTH('数据库')|OCTET_LENGTH('数据库')
--------------------|---------------------
3| 9字符串“数据库”包含3个字符,在UTF-8编码中占用9个字节。MySQL和PostgreSQL实现了这两个标准函数。
Oracle使用LENGTH(s)函数和LENGTHB函数计算字符数量和字节数量,例如:
-- Oracle
SELECT LENGTH('数据库'), LENGTHB('数据库')
FROM dual;查询返回的结果和上面的示例相同。
提示:PostgreSQL也提供了LENGTH(s)函数,用于返回字符串中的字符数量。MySQL也提供了LENGTH(s)函数,用于返回字符串中的字节数量。
Microsoft SQL Server使用LEN(s)函数和DATALENGTH(s)函数计算字符数量和字节数量,例如:
-- Microsoft SQL Server
SELECT LEN('数据库'), DATALENGTH('数据库');查询返回的结果如下。
LEN|DATALENGTH
---|----------
3| 6字符串“数据库”在“Chinese_PRC_CI_AS”字符集中占用6个字节,每个汉字占用2个字节。
SQLite只提供了LENGTH(s)函数,用于计算字符串中的字符个数,例如:
-- SQLite
SELECT LENGTH('数据库');查询返回的结果如下。
LENGTH('数据库')
--------------
32. 连接字符串
CONCAT(s1, s2, …)函数将两个或者多个字符串连接到一起,组成一个新的字符串。例如:
-- MySQL、Microsoft SQL Server以及PostgreSQL
SELECT CONCAT('S', 'Q', 'L');查询返回的结果如下。
CONCAT('S', 'Q', 'L')
---------------------
SQL Oracle中的CONCAT函数一次只能连接两个字符串,例如:
SELECT CONCAT(CONCAT('S', 'Q'), 'L')
FROM dual;我们通过嵌套函数调用连接多个字符串,查询返回的结果和上面的示例相同。
SQLite没有提供连接字符串的函数,可以通过连接运算符(||)实现字符串的连接。例如:
-- SQLite、Oracle以及PostgreSQL
SELECT 'S' || 'Q' || 'L';查询返回的结果和上面的示例相同。
Oracle和PostgreSQL也提供了连接运算符(||),Microsoft SQL Server使用加号(+)作为连接运算符。
除了CONCAT函数之外,还有一个CONCAT_WS(separator, s1, s2 , ... )函数,可以使用指定分隔符连接字符串。例如:
-- MySQL、Microsoft SQL Server以及PostgreSQL
SELECT CONCAT_WS('-','S', 'Q', 'L');查询返回的结果如下。
CONCAT_WS('-','S', 'Q', 'L')
----------------------------
S-Q-L MySQL、Microsoft SQL Server以及PostgreSQL实现了该函数。
3. 大小写转换
LOWER(s)函数将字符串转换为小写,UPPER(s)函数将字符串转换为大写。例如:
SELECT LOWER('SQL'), UPPER('sql')
FROM employee
WHERE emp_id = 1;查询返回的结果如下。
LOWER('SQL')|UPPER('sql')
------------|------------
sql |SQL 提示:MySQL中的LCASE函数等价于LOWER函数,UCASE函数等价于UPPER函数。Oracle和PostgreSQL还提供了首字母大写的INITCAP函数。
4. 获取子串
SUBSTRING(s, n, m)函数返回字符串s中从位置n开始的m个字符子串。例如:
-- MySQL、Microsoft SQL Server、PostgreSQL以及SQlite
SELECT SUBSTRING('数据库', 1, 2);查询返回的结果如下。
SUBSTRING('数据库', 1, 2)
-----------------------
数据 Oracle使用简写的SUBSTR(s, n, m)函数返回子串,例如:
-- Oracle、MySQL、PostgreSQL以及SQLite
SELECT SUBSTR('数据库', 1, 2)
FROM dual;MySQL、PostgreSQL以及SQLite也支持SUBSTR函数。查询结果和上面的示例相同。
另外,Oracle、MySQL以及SQLite中的起始位置n可以指定负数,表示从字符串的尾部倒数查找起始位置,然后再返回子串。例如:
-- Oracle、MySQL以及SQLite
SELECT SUBSTR('数据库', -2, 2)
FROM employee
WHERE emp_id = 1;查询返回的结果如下。
SUBSTR('数据库', -2, 2)
---------------------
据库 其中,-2表示从右往左数第2个字符(“据”),然后再返回2个字符。
提示:MySQL、Microsoft SQL Server以及PostgreSQL提供了LEFT(s, n)和RIGHT(s, n)函数,分别用于返回字符串开头和结尾的n个字符。
5. 子串查找与替换
INSTR(s, s1)函数查找并返回字符串s中子串s1第一次出现的位置,如果没有找到子串则会返回0。例如:
-- Oracle、MySQL以及SQLite
SELECT email, INSTR(email, '@')
FROM employee
WHERE emp_id = 1;查询返回的结果如下。
email |INSTR(email, '@')
-----------------|-----------------
liubei@shuguo.com| 7“@”是字符串“liubei@shuguo.com”中的第7个字符。
Microsoft SQL Server使用PATINDEX(s1, s)函数查找子串的位置,例如:
-- Microsoft SQL Server
SELECT email, PATINDEX('%@%', email)
FROM employee
WHERE emp_id = 1;其中,s1参数的形式为%pattern%,类似于LIKE运算符中的匹配模式。查询返回的结果和上面的示例相同。
PostgreSQL使用POSITION (s1 IN s)函数查找子串的位置,例如:
-- PostgreSQL
SELECT email, POSITION('@' IN email)
FROM employee
WHERE emp_id = 1;查询返回的结果和上面的示例相同。
REPLACE(s, old, new)函数将字符串s中的子串old替换为new。例如:
SELECT email, REPLACE(email, 'com', 'net')
FROM employee
WHERE emp_id = 1;查询返回的结果如下。
email |REPLACE(email, 'com', 'net')
-----------------|----------------------------
liubei@shuguo.com|liubei@shuguo.net REPLACE函数在5种主流数据库中的实现一致。
6. 截断字符串
TRIM(s1 FROM s)函数删除字符串s开头和结尾的子串s1。例如:
-- Oracle、MySQL、Microsoft SQL Server以及PostgreSQL
SELECT TRIM('-' FROM '--S-Q-L--'), TRIM(' S-Q-L ')
FROM employee
WHERE emp_id = 1;第一个函数删除了开头和结尾的“-”;第二个函数省略了s1子串,默认表示删除开头和结尾的空格。查询返回的结果如下。
TRIM('-' FROM '--S-Q-L--')|TRIM(' S-Q-L ')
--------------------------|-----------------
S-Q-L |S-Q-LOracle中的参数s1只能是单个字符,其他数据库中的参数s1可以是多个字符。
SQLite中的TRIM(s, s1)函数的调用格式与其他数据库不同,例如:
-- SQLite
SELECT TRIM('--S-Q-L--', '-'), TRIM(' S-Q-L ');查询返回的结果和上面的示例相同。
提示:LTRIM(s)函数可以删除字符串开头的空格,RTRIM(s)函数可以删除字符串尾部的空格,这两个函数是TRIM函数的简化版。
3.1.4 日期函数
日期函数用于操作日期和时间数据,例如获取当前日期、计算两个日期之间的间隔以及获取日期的部分信息等。表3.3列出了常见的SQL日期函数及它们在5种主流数据库中的实现。
表3.3 常见SQL日期函数与实现
| 日期函数 | 函数功能 | Oracle | MySQL | Microsoft SQL Server | PostgreSQL | SQLite |
| CURRENT_DATE | 返回当前日期 | 支持 | 支持 | GETDATE() | 支持 | 支持 |
| CURRENT_TIME | 返回当前时间 | 不支持 | 支持 | GETDATE() | 支持 | 支持 |
| CURRENT_TIMESTAMP | 返回当前日期和时间 | 支持 | 支持 | 支持 | 支持 | 支持 |
| EXTRACT(p FROM dt) | 提取日期中的部分信息 | 支持 | 支持 | DATEPART(p, dt) | 支持 | STRFTIME |
| dt1 - dt2 | 计算两个日期之间的天数 | 支持 | DATEDIFF(dt2, dt1) | DATEDIFF(p, dt1, dt2) | 支持 | STRFTIME |
| dt + INTERVAL | 日期加上一个时间间隔 | 支持 | 支持 | DATEADD(p, n, dt) | 支持 | STRFTIME |
下面我们通过一些示例来说明这些函数的作用和注意事项。
1. 返回当前日期和时间
CURRENT_DATE、CURRENT_TIME以及CURRENT_TIMESTAMP函数分别返回了数据库系统当前的日期、时间以及时间戳(日期和时间)。例如:
-- MySQL、PostgreSQL以及SQLite
SELECT CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP;查询返回的结果取决于我们执行语句的时间。
CURRENT_DATE|CURRENT_TIME|CURRENT_TIMESTAMP
------------|------------|-------------------
2021-06-20| 15:32:44|2021-06-20 15:32:44Oracle中的日期类型包含了日期和时间信息,不支持时间类型。例如:
-- Oracle
SELECT CURRENT_DATE, CURRENT_TIMESTAMP
FROM dual;查询返回的结果如下。
CURRENT_DATE |CURRENT_TIMESTAMP
-------------------|-------------------
2021-06-20 15:40:27|2021-06-21 15:40:27Microsoft SQL Server中需要使用GETDATE()函数返回当前时间戳,然后通过类型转换函数CAST(expr AS type)将结果转换为日期或者时间类型。例如:
-- Microsoft SQL Server
SELECT CAST(GETDATE() AS DATE), CAST(GETDATE() AS TIME), CURRENT_TIMESTAMP;下一小节我们将会介绍类型转换函数,查询返回的结果如下。
DATE |TIME |CURRENT_TIMESTAMP
----------|--------|-------------------
2021-06-20|15:47:47|2021-06-20 15:47:472. 提取日期中的部分信息
EXTRACT(p FROM dt)函数提取日期时间中的部分信息,例如年、月、日、时、分、秒等。例如:
-- Oracle、MySQL以及PostgreSQL
SELECT EXTRACT(YEAR FROM hire_date)
FROM employee
WHERE emp_id = 1;函数参数中的YEAR表示提取年份信息,查询返回的结果如下。
EXTRACT(YEAR FROM hire_date)
----------------------------
2000除了提取年份信息之外,我们也可以使用MONTH、DAY、HOUR、MINUTE、SECOND等参数提取日期中的其他信息。
Microsoft SQL Server使用DATEPART(p, dt)函数提取日期中的信息。例如:
-- Microsoft SQL Server
SELECT DATEPART(YEAR, hire_date)
FROM employee
WHERE emp_id = 1;函数参数中的YEAR表示提取年份信息,同样也可以使用MONTH、DAY、HOUR、MINUTE、SECOND等参数提取日期中的其他信息。查询返回的结果与上面的示例相同。
SQLite提供了日期格式化函数STRFTIME,可以提取日期中的信息。例如:
-- SQLite
SELECT STRFTIME('%Y', hire_date)
FROM employee
WHERE emp_id = 1;函数中的第一个参数%Y代表4位数的年份,我们也可以使用%m、%d、%H、%M、%S等参数提取日期中的其他信息。查询返回的结果与上面的示例相同。
3. 日期的加减运算
日期的加减运算主要包括两个日期相减以及一个日期加/减一个时间间隔。例如:
-- Oracle和PostgreSQL
SELECT DATE '2021-03-01' - DATE '2021-02-01',
DATE '2021-02-01' + INTERVAL '-1' MONTH
FROM employee
WHERE emp_id = 1;Oracle和PostgreSQL中两个日期相减就可以得到它们之间相差的天数,日期加上一个时间间隔(INTERVAL)就可以得到一个新的日期。查询返回的结果如下。
DATE'2021-03-01'-DATE'2021-02-01'|DATE'2021-02-01'+INTERVAL'-1'MONTH
---------------------------------|----------------------------------
28| 2021-01-01 00:00:002021年2月份有28天,2021年2月1日减去一个月是2021年1月1日。
MySQL使用DATEDIFF(dt2, dt1)函数计算日期dt2减去日期dt1得到的天数,例如:
-- MySQL
SELECT DATEDIFF(DATE '2021-03-01', DATE '2021-02-01'),
DATE '2021-02-01' + INTERVAL '-1' MONTH;查询返回的结果和上面的示例相同。
Microsoft SQL Server 使用DATEDIFF(p, dt1, dt2)函数计算日期dt2减去日期dt1得到的时间间隔,使用DATEADD(p, n, dt)函数为日期增加一个时间间隔。例如:
-- Microsoft SQL Server
SELECT DATEDIFF(DAY, '2021-02-01', '2021-03-01'),
DATEADD(MONTH, -1, '2021-02-01');DATEDIFF函数中的第一个参数(DAY)表示计算第二个日期减去第一个日期的天数,也可以返回月数(MONTH)或者年数(YEAR)等。DATEADD函数在2021年2月1日的基础上增加了-1个月,也就是减去1个月。查询返回的结果和上面的示例相同。
SQLite可以利用STRFTIME函数实现两个日期的相减或者为日期增加一个时间间隔。例如:
-- SQLite
SELECT STRFTIME('%J', '2021-03-01') - STRFTIME('%J', '2021-02-01'),
STRFTIME('%Y-%m-%d', '2021-02-01', '-1 months');前两个STRFTIME函数中的参数%J表示将日期转换为儒略日(Julian Day)。第3个STRFTIME函数格式化日期的同时增加了一个时间间隔。查询返回的结果和上面的示例相同。
3.1.5 转换函数
当不同类型的数据在一起进行计算时,就会涉及数据类型之间的转换。我们可以使用函数进行明确的类型转换,数据库也可能执行隐式的类型转换。
CAST(expr AS type)函数用于将数据转换为其他的类型。例如:
-- Oracle、Microsoft SQL Server、PostgreSQL以及SQLite
SELECT CAST('123' AS INTEGER)
FROM employee
WHERE emp_id = 1;我们通过CAST函数将字符串“123”转换成了数字123。查询返回的结果如下。
CAST('123' AS INTEGER)
----------------------
123MySQL中的整型分为有符号整数SIGNED INTEGER和无符号整数UNSIGNED INTEGER。例如:
-- MySQL
SELECT CAST('123' AS UNSIGNED INTEGER);需要注意,类型转换可能导致精度的丢失,而且CAST函数在各个数据库中支持的转换类型取决于数据库的实现。
除了我们在SQL语句中明确指定类型转换之外,数据库也可能在执行某些操作时尝试隐式的类型转换。例如:
-- Oracle、MySQL、Microsoft SQL Server、以及PostgreSQL
SELECT '666' + 123, CONCAT('Hire Date: ', hire_date)
FROM employee
WHERE emp_id = 1;查询返回的结果如下。
'666' + 123|CONCAT('Date: ', hire_date)
-----------|---------------------------
789|Hire Date: 2000-01-01 该查询中存在2个隐式类型转换,第1个类型转换将字符串“666”转换为数字666,第2个类型转换将日期类型的hire_date转换为字符串。
3.1.6 案例分析
接下来我们通过两个案例分析进一步理解SQL函数的使用。
1. 公司年会抽奖
很多公司都会在年终大会上提供抽奖环节,假如现在我们需要设计一个抽奖程序,每次从员工表中随机抽取一名中奖员工,如何通过SQL语句实现?方法就是利用随机数函数为员工表中的每行数据指定一个随机顺序,然后排序并返回第1条记录。我们以MySQL为例:
-- MySQL
SELECT emp_id, emp_name
FROM employee
ORDER BY RAND()
LIMIT 1;我们每次执行以上查询都会返回不同的员工,例如:
emp_id|emp_name
------|--------
18|法正 这种方法可能会导致同一个员工中将多次,简单的处理方式就是再执行一次查询。
提示:另一种方式就是创建一个中奖员工表,每次抽奖后将中奖员工编号插入该表,下次抽奖时通过NOT IN子查询排除已经中奖的员工。我们将会在第7章中介绍子查询。
其他数据库的实现与MySQL类似,我们只需要替换相应的随机数函数和限制返回数据的LIMIT子句。不过在Microsoft SQL Server中我们不能直接使用RAND()函数,因为该函数在一次查询中返回的随机数都相同。我们可以利用NEWID()函数返回一个随机的GUID作为排序的标准,例如:
-- Microsoft SQL Server
SELECT emp_id, emp_name
FROM employee
ORDER BY NEWID()
OFFSET 0 ROWS
FETCH FIRST 1 ROWS ONLY;这种方法本质上仍然是利用了随机数。
2. 保护个人隐私
姓名、身份证号以及银行卡号等属于个人敏感信息。为了保护个人隐私,我们在前端界面显示时可能需要将这些信息中的部分内容进行隐藏,也就是显示为星号(*)。以医院排队叫号系统为例,屏幕上通常会隐藏患者的姓氏(对于两个字的姓名)或者名字中的倒数第2个字(对于三个或更多字的姓名),例如“*三”或者“李*亮”。
我们首先来看如何在MySQL和PostgreSQL中实现这个功能:
-- MySQL和PostgreSQL
SELECT emp_name,
CONCAT(LEFT(emp_name, CHAR_LENGTH(emp_name
)-2),
'*', RIGHT(emp_name, 1))
FROM employee
WHERE emp_id <= 5;其中,LEFT函数返回了姓名中倒数第2个字之前的内容,CHAR_LENGTH函数返回了姓名中的字符个数,星号(*)替代了姓名中的倒数第2个字,RIGHT函数返回了姓名中的最后1个字,CONCAT函数将所有内容连接成一个字符串。查询返回的结果如下。
emp_name|CONCAT
--------|------
刘备 |*备
关羽 |*羽
张飞 |*飞
诸葛亮 |诸*亮
黄忠 |*忠 其他数据库中的实现与此类似,例如:
-- Oracle和SQLite
SELECT emp_name,
SUBSTR(emp_name, 1, LENGTH(emp_name)-2)||'*'||SUBSTR(emp_name, -1, 1)
FROM employee
WHERE emp_id <= 5;
-- Microsoft SQL Server
SELECT emp_name,
CONCAT(LEFT(emp_name, LEN(emp_name)-2), '*', RIGHT(emp_name, 1))
FROM employee
WHERE emp_id <= 5;Oracle和SQLite利用SUBSTR函数返回姓名中的部分内容,并且使用连接运算符(||)替代CONCAT函数。Microsoft SQL Server使用LEN函数返回姓名中的字符个数。
3.2 使用别名
当查询语句中使用了函数或者表达式时,返回字段的名称通常比较复杂。为了提高查询结果的可读性,我们可以使用别名(Alias)为查询中的表或者字段指定一个更有意义的名称。
3.2.1 列别名
SQL通过关键字AS指定别名,为字段指定的别名被称为列别名。例如:
SELECT emp_name AS "员工姓名",
salary * 12 + bonus AS "年薪",
email "电子邮箱"
FROM employee
WHERE emp_id <= 3;列别名中的AS关键字可以省略,只需要保留一个空格。当列别名中包含空格或者特殊字符时需要使用引号引用,一般使用双引号。查询返回的结果如下。
员工姓名|年薪 |电子邮箱
-------|----------|-------------------
刘备 |370000.00 |liubei@shuguo.com
关羽 |322000.00 |guanyu@shuguo.com
张飞 |298000.00 |zhangfei@shuguo.com3.2.2 表别名
除了列别名之外,我们也可以为查询语句中的表指定一个表别名。例如:
SELECT e.emp_name AS "员工姓名",
e.salary * 12 + bonus AS "年薪",
e.email "电子邮箱"
FROM employee AS e
WHERE e.emp_id <= 3;Oracle中的表别名不支持AS关键字,直接在表名后加上空格和别名。其他数据库中的AS关键字也可以省略。
在上面的查询中我们为employee表指定了一个别名e,然后使用表别名对字段进行限定,表示要返回哪个表中的字段,例如e.emp_name表示员工表中的员工姓名字段。当查询涉及多个表或者子查询时,表别名可以帮助我们更好地理解字段的来源。
提示:在SQL语句中使用别名不会修改数据库中存储的表名或者列名。别名是一个临时的名称,只在当前语句中有效。
3.3 条件表达式
SQL条件表达式(CASE)可以基于不同条件产生不同的结果,实现类似于编程语言中的IF-THEN-ELSE逻辑处理功能。例如,根据员工的KPI计算相应的涨薪幅度,根据学生考试成绩评出优秀、良好、及格等。
SQL条件表达式支持两种形式:简单CASE表达式和搜索CASE表达式。
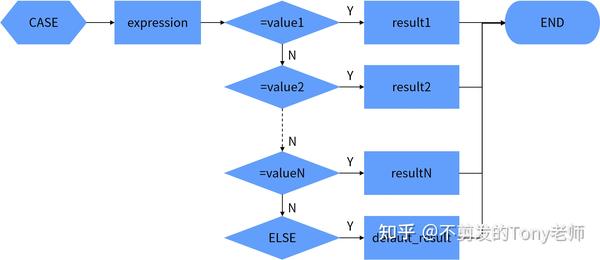
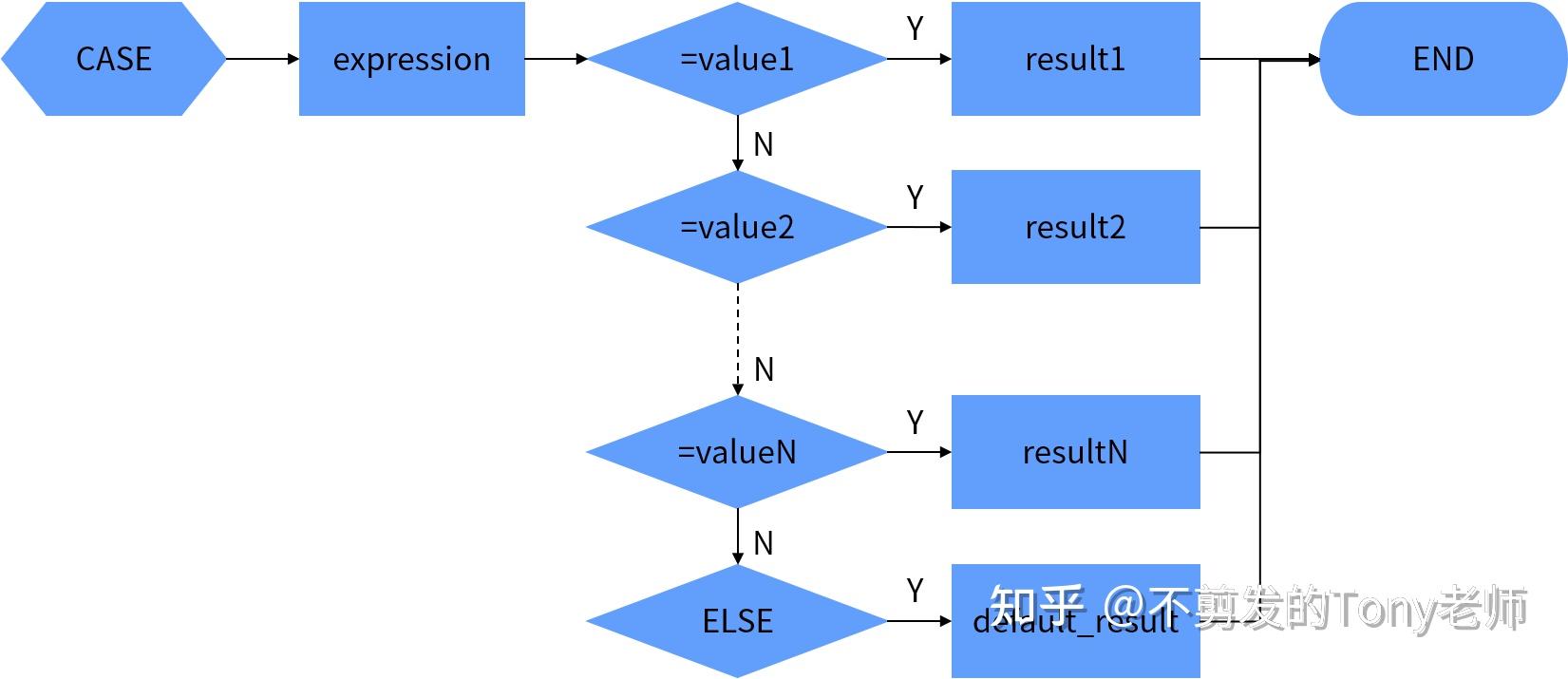
3.3.1 简单CASE表达式
简单CASE表达式的语法如下:
CASE expression
WHEN value1 THEN result1
WHEN value2 THEN result2
[ELSE default]
END语句执行时首先计算expression的值,然后和第1个WHEN子句中的数据(value1)进行比较,如果相等则返回对应THEN子句中的结果(result1);如果不相等则继续和第2个WHEN子句中的数据(value2)进行比较,如果相等则返回对应THEN子句中的结果(result2);依此类推,如果没有找到相等的数据,返回ELSE子句中的默认结果(default);如果没有指定ELSE子句,返回空值。
简单CASE达式的计算过程如图3.1所示。
例如,以下查询使用简单CASE表达式将员工的部门编号转换为相应的名称:
SELECT emp_name,
CASE dept_id
WHEN 1 THEN '行政管理部'
WHEN 2 THEN '人力资源部'
WHEN 3 THEN '财务部'
WHEN 4 THEN '研发部'
WHEN 5 THEN '销售部'
WHEN 6 THEN '保卫部'
ELSE '其他部门'
END AS "部门名称"
FROM employee;查询返回的结果如下。
员工姓名|部门编号|部门名称
------|-------|--------
刘备 | 1|行政管理部
关羽 | 2|行政管理部
张飞 | 3|行政管理部
诸葛亮 | 4|人力资源部
黄忠 | 5|人力资源部
魏延 | 6|人力资源部
孙尚香 | 7|财务部
孙丫鬟 | 8|财务部
...简单CASE表达式在进行条件判断时使用的是等值比较(=),只能处理简单的比较逻辑。如果想要实现复杂的逻辑处理,例如根据学生考试成绩范围评出优秀、良好等,需要使用更加强大的搜索CASE表达式。
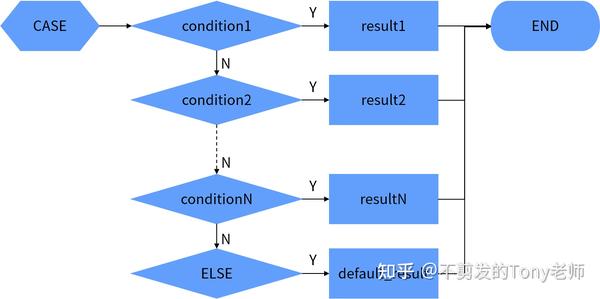
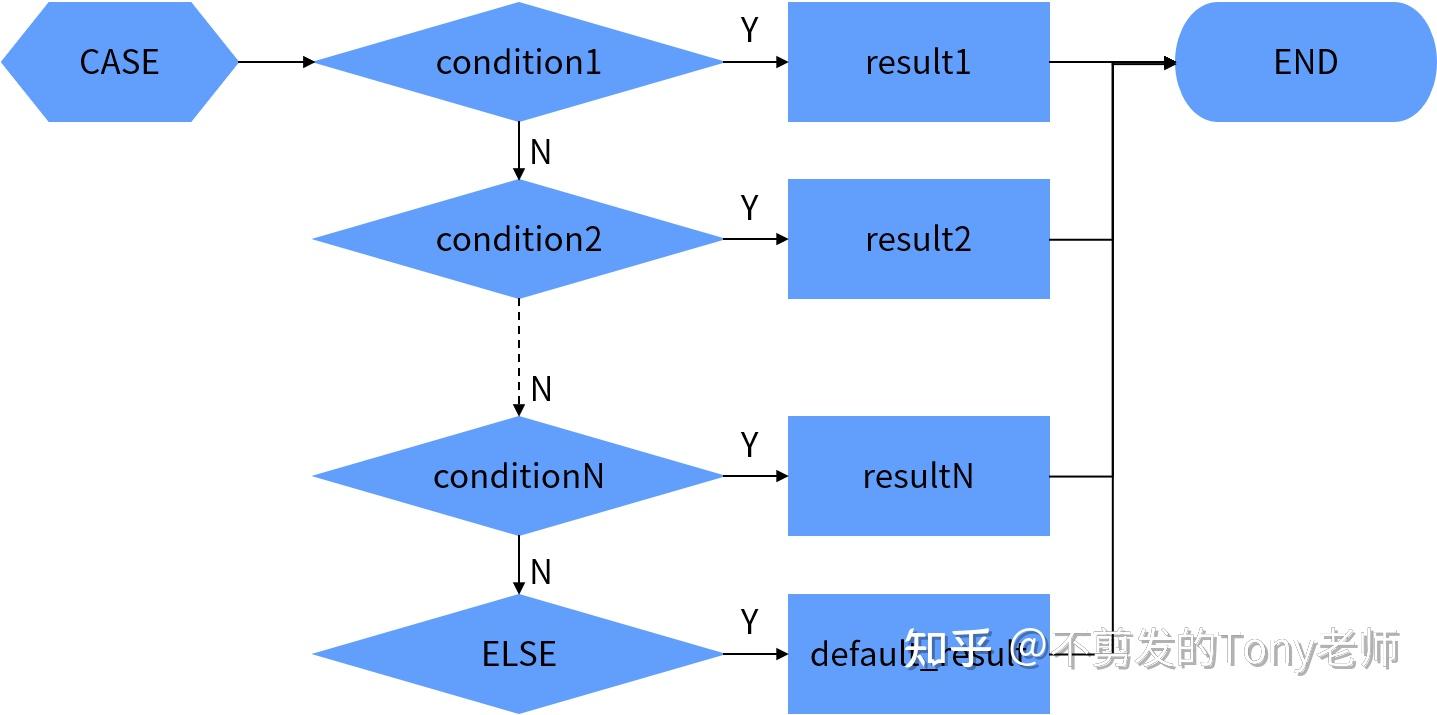
3.3.2 搜索CASE表达式
搜索CASE表达式的语法如下:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
[ELSE default]
END语句执行时首先判断第1个WHEN子句中的条件(condition1)是否成立,如果成立则返回对应THEN子句中的结果(result1);如果不成立则继续判断第2个WHEN子句中的条件(condition2)是否成立,如果成立则返回对应THEN子句中的结果(result2);依此类推,如果没有任何条件成立,返回ELSE子句中的默认结果(default);如果没有指定ELSE子句,返回空值。
搜索CASE达式的计算过程如图3.2所示。
前文中的简单CASE表达式示例可以使用等价的搜索CASE表达式实现如下:
SELECT emp_name AS "员工姓名",emp_id AS "部门编号",
WHEN dept_id = 1 THEN '行政管理部'
WHEN dept_id = 2 THEN '人力资源部'
WHEN dept_id
= 3 THEN '财务部'
WHEN dept_id = 4 THEN '研发部'
WHEN dept_id = 5 THEN '销售部'
WHEN dept_id = 6 THEN '保卫部'
ELSE '其他部门'
END AS "部门名称"
FROM employee;搜索CASE表达式中的判断条件可以像WHERE子句中的过滤条件一样复杂。例如,以下查询基于员工的月薪将他们的收入分为“高”、“中”、“低”三个级别:
SELECT emp_name AS "员工姓名",salary AS "月薪",
WHEN salary < 10000 THEN '低收入'
WHEN salary < 20000 THEN '中收入'
ELSE '高收入'
END AS "收入级别"
FROM employee;月薪小于10000时返回“低收入”;否则,如果月薪小于20000(大于等于10000)返回“中收入”;否则,月薪大于等于20000,返回“高收入”。查询返回的结果如下。
员工姓名|月薪 |收入级别
-------|--------|-------
刘备 |30000.00|高收入
关羽 |26000.00|高收入
张飞 |24000.00|高收入
诸葛亮 |24000.00|高收入
黄忠 | 8000.00|低收入
魏延 | 7500.00|低收入
孙尚香 |12000.00|中收入
孙丫鬟 | 6000.00|低收入
...CASE表达式也可以在其他子句中使用,包括WHERE、ORDER BY等子句。例如,以下语句使用CASE表达式实现了空值的自定义排序:
SELECT emp_name AS "员工姓名",
WHEN bonus IS NULL THEN 0
ELSE bonus
END AS "奖金"
FROM employee
WHERE dept_id = 2
ORDER BY CASE
WHEN bonus IS NULL THEN 0
ELSE bonus
END;其中,ORDER BY子句中的CASE表达式将bonus为空的数据转换为0,从而实现了空值排在最前的效果。查询返回的结果如下。
员工姓名|奖金
-------|-------
黄忠 | 0
魏延 | 0
诸葛亮 |8000.00CASE表达式是SQL中的一个非常实用的功能,而且在5种数据库中的实现一致。除了标准的CASE表达式之外,一些数据库还提供了专有的扩展函数。
3.3.3 DECODE函数
Oracle提供了一个DECODE函数,可以实现类似于简单CASE表达式的功能。该函数的语法如下:
DECODE(expression, value1, result1, value2, result2, ...[, default ])函数执行时依次比较表达式expression与valueN的值,如果找到相等的值则返回对应的 resultN;如果没有找到任何相等的值,返回默认值default;如果没有指定默认值则,返回空值。
前文中的简单CASE表达式示例可以使用DECODE函数实现如下:
-- Oracle
SELECT emp_name,
DECODE(dept_id, 1, '行政管理部', 2, '人力资源部',
3 ,'财务部', 4, '研发部',
5, '销售部', 6, '保卫部', '其他部门'
) AS "部门名称"
FROM employee;虽然Oracle提供了DECODE函数,但是它不具有移植性,而且只能实现简单逻辑处理,推荐使用标准的CASE表达式。
3.3.4 IF函数
MySQL提供了一个IF(expr1, expr2, expr3)函数,如果表达式expr1的结果为真(不等于0或者不是空值),返回表达式expr2的值;否则,返回表达式expr3的值。例如:
-- MySQL
SELECT IF(1<2, '1<2', '1>=2') AS result;查询返回的结果如下。
result
------
1<2 3.3.5 IIF函数
Microsoft SQL Server和SQLite提供了一个IIF(boolean_expression, true_value, false_value)函数,如果表达式boolean_expression的结果为真,返回表达式true_value的值,否则返回表达式false_value的值。例如:
-- Microsoft SQL Server和SQLite
SELECT IIF(1<2, '1<2', '1>=2') AS result;查询返回的结果和上面的IF函数示例相同。
3.3.6 案例分析
假如公司即将成立20周年,打算给全体员工发放一个周年庆礼品。发放礼品的规则如下:
- 截至2020年入职年限不满10年的员工,男性员工的礼品为手表一块,女性员工的礼品为化妆品一套;
- 截至2020年入职年限满10年不满15年的员工,男性员工的礼品为手机一部,女性员工的礼品为项链一条;
- 截至2020入职年限满15年的员工,不论男女礼品统一为电脑一台。
现在人事部门需要知道为每位员工发放什么礼品,如何通过查询语句得到这些信息?
搜索CASE表达式非常合适这类逻辑条件的处理,我们可以使用以下语句:
-- Oracle、MySQL以及PostgreSQL
SELECT emp_name AS "员工姓名", hire_date AS "入职日期",
WHEN EXTRACT(YEAR FROM hire_date)> 2011 AND sex = '男' THEN '手表'
WHEN EXTRACT(YEAR FROM hire_date) > 2011 AND sex = '女' THEN '化妆品'
WHEN EXTRACT(YEAR FROM hire_date) > 2006 AND sex = '男' THEN '手机'
WHEN EXTRACT(YEAR FROM hire_date) > 2006 AND sex = '女' THEN '项链'
ELSE '电脑'
END AS "礼品"
FROM employee;除了搜索CASE表达式之外,我们还使用了EXTRACT函数提取员工的入职年份,因此以上查询适用于Oracle、MySQL以及PostgreSQL。
查询返回的结果如下。
员工姓名|入职日期 |礼品
------|----------|---
刘备 |2000-01-01|电脑
关羽 |2000-01-01|电脑
张飞 |2000-01-01|电脑
廖化 |2009-02-17|手机
关平 |2011-07-24|手机
赵氏 |2011-11-10|项链
...Microsoft SQL Server可以使用DATAPART函数提取日期中的信息,例如:
-- Microsoft SQL Server
SELECT emp_name AS "员工姓名", hire_date AS "入职日期",
WHEN DATEPART(YEAR, hire_date) > 2011 AND sex = '男' THEN '手表'
WHEN DATEPART(YEAR, hire_date) > 2011 AND sex = '女' THEN '化妆品'
WHEN DATEPART(YEAR, hire_date) > 2006 AND sex = '男' THEN '手机'
WHEN DATEPART(YEAR, hire_date) > 2006 AND sex = '女' THEN '项链'
ELSE '电脑'
END AS "礼品"
FROM employee;SQLite可以使用STRFTIME函数提取日期中的信息,例如:
-- SQLite
SELECT emp_name AS "员工姓名", hire_date AS "入职日期",
WHEN CAST(STRFTIME('%Y', hire_date) AS INT) > 2011 AND sex = '男'
THEN '手表'
WHEN CAST(STRFTIME('%Y', hire_date) AS INT) > 2011 AND sex = '女'
THEN '化妆品'
WHEN CAST(STRFTIME('%Y', hire_date) AS INT) > 2006 AND sex = '男'