

你应该知道的PostgreSQL分区表知识

为什么需要分区表?
首先我们需要思考一个问题,为什么需要分区表?
对,没错,就是因为Big Table的性能差,而且容量有上限,所以才需要
分而治之
。一张表最大的容量是2^32次方的Page页面,而Page默认值是8K,所以一张表最大的上限是32TB,如果你把Page大小改成32KB,则单表大小可以达到128TB。但是在使用分区表的情况下,一个表可以获得2^32个子表,每个子表的大小又能达到2 ^ 32 * 8192字节。所以使用了分区表就不用担心容量上限的问题了。
至于性能差,我们这里可以看一下
2ndquadrant
的一个PPT中关于Big Table的基准测试。
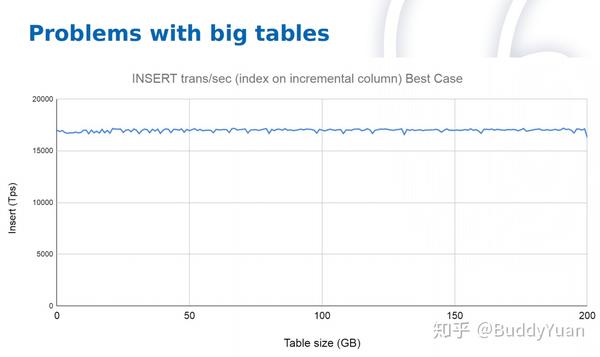
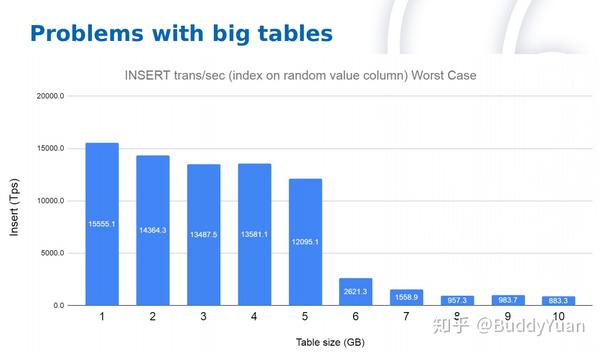
从这两张图可以看出,当大量的insert情况下,如果存在索引,且上面存在自动增长列的时候,表一直增大也没有性能问题。而一旦表上的索引,没有自动增长列处于随机插入的时候,表大小达到6GB后,TPS就急剧下降好几倍,这种下降严重影响性能。
PostgreSQL分区表介绍?
PostgreSQL的分区表有两种形式,一种是
声明式分区
,在PostgreSQL 10版本开始支持。另外一种是
表继承
的方式,是10版本以前主要使用方式。两者的区别就是使用继承的方式需要使用约束来定义分区和规则,还需要使用触发器将数据路由到适合的分区,用户必须编写和维护这些代码。
以下是
表继承
的实现步骤:
- 创建父表,所有分区都将从该表继承。
- 创建几个子表(每个子表代表数据分区),每个表均从父表继承。
- 向分区表添加约束,以定义每个分区中的行值。
-
分别在父表和子表上创建索引。(索引不会从父表传播到子表)。
-
在主表上创建一个合适的触发器函数,以便将插入到父表中的内容重定向到相应的分区表中。
- 创建一个调用该触发器函数的触发器。
注:当子表规则发生变化时,要重新定义触发器函数。
表继承
相当的复杂。而
声明式分区
则简单许多。它的实现步骤如下:
-
使用
PARTITION BY子句创建一个分区表,该子句包含了分区方法,可以使用Range、List、Hash三种方式。 - 创建分区表后,可以手动创建子分区。
- 然后在子分区上创建索引。
声明式分区
大大简化了
表继承
的若干过程,对用户来说更简单。插入自动化(勿需触发器)和直接对分区表进行操作更加简单和人性化。
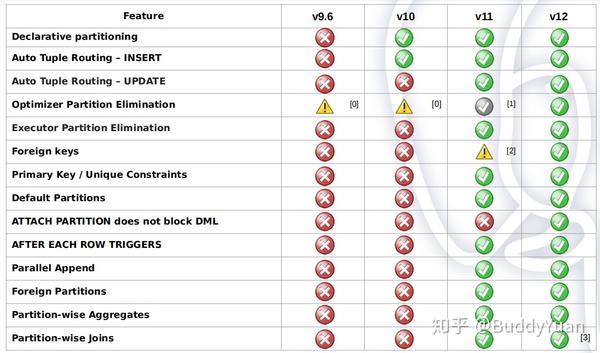
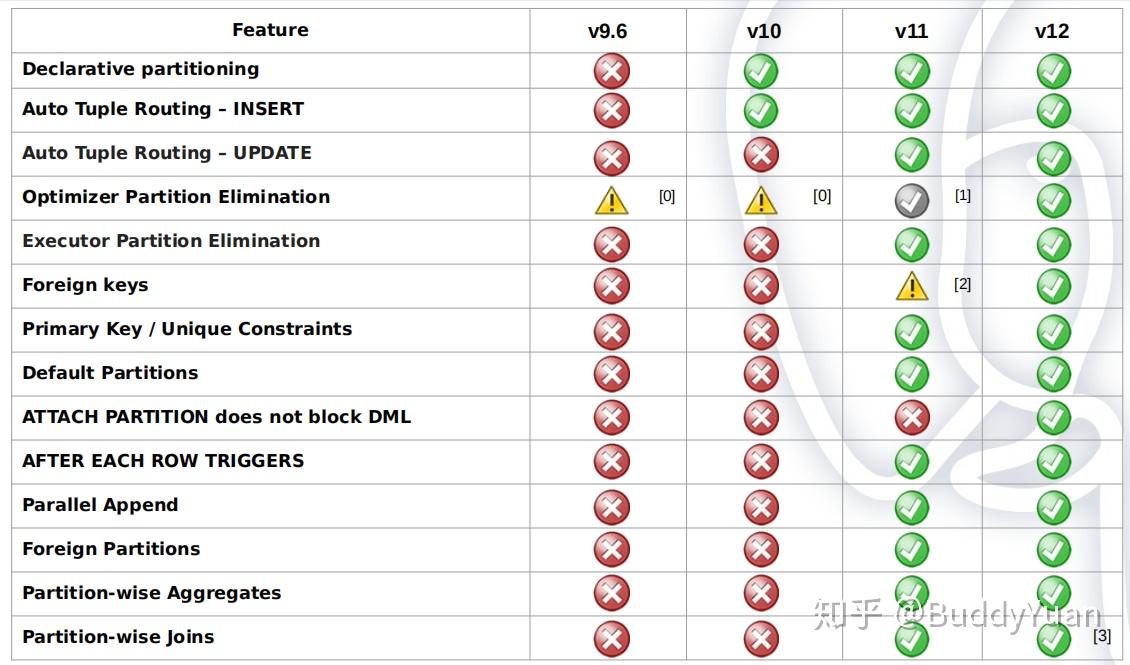
下图是各个版本对分区功能的支持,在PostgreSQL 10版本中,声明式分区功能还比较弱,要到11版本声明式分区才会有大幅的提升。
PostgreSQL分区表基本使用
接下来我们来使用一下PostgreSQL的分区表功能,我们采用的是
声明式分区
方式。
List分区
列表分区明确指定根据某字段的某个具体值进行分区,默认分区(可选值)保存不属于任何指定分区的列表值。
CREATE TABLE students (id INTEGER, status character varying(30), name character varying(30)) PARTITION BY LIST(status);
CREATE TABLE stu_active PARTITION OF students FOR VALUES IN ('ACTIVE');
CREATE TABLE stu_exp PARTITION OF students FOR VALUES IN ('EXPIRED');
CREATE TABLE stu_others PARTITION OF students DEFAULT;
postgres=# \d+ students
Partitioned table "public.students"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
name | character varying(30) | | | | extended | |
Partition key: LIST (status)
Partitions: stu_active FOR VALUES IN ('ACTIVE'),
stu_exp FOR VALUES IN ('EXPIRED'),
stu_others DEFAULT
postgres=# \d+ stu_active
Table "public.stu_active"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
name | character varying(30) | | | | extended | |
Partition of: students FOR VALUES IN ('ACTIVE')
Partition constraint: ((status IS NOT NULL) AND ((status)::text = 'ACTIVE'::character varying(30)))
Access method: heap
postgres=# INSERT INTO students VALUES (1,'ACTIVE','zhangyit'), (2,'EXPIRED','lias'), (3,'EXPIRED','wangwei'), (4,'REACTIVATED','liulah');
postgres=# select tableoid::regclass,* from students;
tableoid | id | status | name
------------+----+-------------+----------
stu_active | 1 | ACTIVE | zhangyit
stu_exp | 2 | EXPIRED | lias
stu_exp | 3 | EXPIRED | wangwei
stu_others | 4 | REACTIVATED | liulahRange分区
范围分区就是根据某个字段值的范围来进行分区。
CREATE TABLE students (id INTEGER, status character varying(30), grade INTEGER) PARTITION BY RANGE(grade);
CREATE TABLE stu_fail PARTITION OF students FOR VALUES FROM (MINVALUE) TO (60);
CREATE TABLE stu_pass PARTITION OF students FOR VALUES FROM (60) TO (75);
CREATE TABLE stu_excellent PARTITION OF students FOR VALUES FROM (75) TO (MAXVALUE);
postgres=# \d+ students
Partitioned table "public.students"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition key: RANGE (grade)
Partitions: stu_excellent FOR VALUES FROM (75) TO (MAXVALUE),
stu_fail FOR VALUES FROM (MINVALUE) TO (60),
stu_pass FOR VALUES FROM (60) TO (75)
postgres=# \d+ stu_fail
Table "public.stu_fail"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition of: students FOR VALUES FROM (MINVALUE) TO (60)
Partition constraint: ((grade IS NOT NULL) AND (grade < 60))
Access method: heap
postgres=# \d+ stu_pass
Table "public.stu_pass"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition of: students FOR VALUES FROM (60) TO (75)
Partition constraint: ((grade IS NOT NULL) AND (grade >= 60) AND (grade < 75))
Access method: heap
postgres=# \d+ stu_excellent
Table "public.stu_excellent"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition of: students FOR VALUES FROM (75) TO (MAXVALUE)
Partition constraint: ((grade IS NOT NULL) AND (grade >= 75))
Access method: heap
postgres=# INSERT INTO students VALUES (1,'ACTIVE',58), (2,'ACTIVE',60), (3,'ACTIVE',75), (4,'ACTIVE',90);
INSERT 0 4
postgres=# select tableoid::regclass,* from students;
tableoid | id | status | grade
---------------+----+--------+-------
stu_fail | 1 | ACTIVE | 58
stu_pass | 2 | ACTIVE | 60
stu_excellent | 3 | ACTIVE | 75
stu_excellent | 4 | ACTIVE | 90注意:minvalue的上限值是小于,不是小于等于。而maxvalue的区间的下限是大于等于,不是大于。
Hash分区
通过对每个分区使用取模和余数来创建hash分区,modulus指定了对N取模,而remainder指定了除完后的余数。
CREATE TABLE students (id INTEGER, status character varying(30), grade INTEGER) PARTITION BY HASH(id);
CREATE TABLE stu_part1 PARTITION OF students FOR VALUES WITH (modulus 3, remainder 0);
CREATE TABLE stu_part2 PARTITION OF students FOR VALUES WITH (modulus 3, remainder 1);
CREATE TABLE stu_part3 PARTITION OF students FOR VALUES WITH (modulus 3, remainder 2);
postgres=# \d+ stu_part1
Table "public.stu_part1"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition of: students FOR VALUES WITH (modulus 3, remainder 0)
Partition constraint: satisfies_hash_partition('20026077'::oid, 3, 0, id)
Access method: heap
postgres=# \d+ stu_part2
Table "public.stu_part2"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition of: students FOR VALUES WITH (modulus 3, remainder 1)
Partition constraint: satisfies_hash_partition('20026077'::oid, 3, 1, id)
Access method: heap
postgres-# \d+ stu_part3
Table "public.stu_part3"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition of: students FOR VALUES WITH (modulus 3, remainder 2)
Partition constraint: satisfies_hash_partition('20026077'::oid, 3, 2, id)
Access method: heap
postgres=# INSERT INTO students VALUES (1,'ACTIVE',58), (2,'ACTIVE',60), (3,'ACTIVE',75), (4,'ACTIVE',90);
INSERT 0 4
postgres=# select tableoid::regclass,* from students;s
tableoid | id | status | grade
-----------+----+--------+-------
stu_part1 | 2 | ACTIVE | 60
stu_part1 | 4 | ACTIVE | 90
stu_part2 | 3 | ACTIVE | 75
stu_part3 | 1 | ACTIVE | 58我们还可以建立子分区,也就是多级分区,使用PostgreSQL声明性分区的创建子分区方法有:LIST-LIST,LIST-RANGE,LIST-HASH,RANGE-RANGE,RANGE-LIST,RANGE-HASH,HASH-HASH,HASH-LIST和HASH-RANGE。
分区表转换成普通表
我们可以使用
DETACH PARTITION
命令把分区表转换成普通表。
postgres=# alter table students detach partition stu_part3;
ALTER TABLE
postgres=# \d+ students
Partitioned table "public.students"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition key: HASH (id)
Partitions: stu_part1 FOR VALUES WITH (modulus 3, remainder 0),
stu_part2 FOR VALUES WITH (modulus 3, remainder 1)
postgres=# \d+ stu_part3
Table "public.stu_part3"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Access method: heap普通表转换成分区表
我们也可以把某个普通表在附加到分区表上去,使用
attach partition
命令。
postgres=# alter table students attach partition stu_part3 FOR VALUES WITH (modulus 3, remainder 2);
ALTER TABLE
postgres=# \d+ students
Partitioned table "public.students"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition key: HASH (id)
Partitions: stu_part1 FOR VALUES WITH (modulus 3, remainder 0),
stu_part2 FOR VALUES WITH (modulus 3, remainder 1),
stu_part3 FOR VALUES WITH (modulus 3, remainder 2)
postgres=# \d+ stu_part3
Table "public.stu_part3"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
status | character varying(30) | | | | extended | |
grade | integer | | | | plain | |
Partition of: students FOR VALUES WITH (modulus 3, remainder 2)
Partition constraint: satisfies_hash_partition('20026077'::oid, 3, 2, id)
Access method: heap附加上去的表必须具有相同的列/类型,不能存在额外的列。
在运行ATTACH PARTITION命令之前,建议在要附加的表上创建一个与所需分区约束匹配的约束。这样,系统将能够跳过扫描以验证隐式分区约束。如果没有约束,则将扫描附加表以验证分区约束正确性,同时对该分区持有ACCESS EXCLUSIVE锁定,并在父表上持有SHARE UPDATE EXCLUSIVE锁。 在完成ATTACH PARTITION后,可能需要删除冗余CHECK约束。
分区裁剪
分区裁剪就是当已知分区不包含我们要的数据时,在查询的时候就不扫描这个分区,以获得更高的性能。在PostgreSQL 10中,这种消除是通过
constraint_exclusion
机制来实现的,这种机制是一种线性算法,需要一个一个地查看每个分区的元数据,以检查该分区是否与查询WHERE子句匹配,很显然这种效率并不高。而在PostgreSQL 11版本引入了新的算法,不再是详尽的搜索,而使用二分查找法搜索,可以快速识别匹配的LIST和RANGE分区,而HASH分区则通过散列函数查找匹配的分区。
PostgreSQL 11版本该功能通过参数
enable_partition_pruning
进行控制。默认是打开的。
postgres=# explain analyze select * from students where id in (1,2);
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Append (cost=0.00..37.82 rows=14 width=86) (actual time=0.048..0.066 rows=2 loops=1)
-> Seq Scan on stu_part1 (cost=0.00..18.88 rows=7 width=86) (actual time=0.046..0.049 rows=1 loops=1)
Filter: (id = ANY ('{1,2}'::integer[]))
Rows Removed by Filter: 1
-> Seq Scan on stu_part3 (cost=0.00..18.88 rows=7 width=86) (actual time=0.013..0.014 rows=1 loops=1)
Filter: (id = ANY ('{1,2}'::integer[]))
Planning Time: 0.309 ms
Execution Time: 0.118 ms
(8 rows)
postgres=# set enable_partition_pruning=off;
postgres=# explain analyze select * from students where id in (1,2);
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Append (cost=0.00..56.73 rows=21 width=86) (actual time=0.054..0.070 rows=2 loops=1)
-> Seq Scan on stu_part1 (cost=0.00..18.88 rows=7 width=86) (actual time=0.049..0.052 rows=1 loops=1)
Filter: (id = ANY ('{1,2}'::integer[]))
Rows Removed by Filter: 1
-> Seq Scan on stu_part2 (cost=0.00..18.88 rows=7 width=86) (actual time=0.006..0.006 rows=0 loops=1)
Filter: (id = ANY ('{1,2}'::integer[]))
Rows Removed by Filter: 1
-> Seq Scan on stu_part3 (cost=0.00..18.88 rows=7 width=86) (actual time=0.005..0.006 rows=1 loops=1)
Filter: (id = ANY ('{1,2}'::integer[]))
Planning Time: 0.322 ms
Execution Time: 0.133 ms
(11 rows)参数为on的时候,只扫描了2个分区。而将参数改成off之后,会对所有表分区进行扫描。
Run-time 分区剪裁
PostgreSQL 11还有一项新技术就是Run-time分区剪裁,就是在执行时对分区进行裁剪。在某些情况下,这是一个优点。例如PREPARE查询,子查询的值、嵌套循环连接的内层参数值,这些都只有在SQL运行的时候才能知道具体的值。Run-time 分区剪裁发生有以下两种类型。
第一类,就是执行期间参数不变的情况。
下面案例将参数$ 1设置为70,并且该值在整个查询执行过程中不会更改,初始化Append节点时会进行剪裁。
[postgres@paas-telepg-test3 ~]$ psql
psql (12.3)
Type "help" for help.
postgres=# PREPARE a1 (INT) AS SELECT * FROM students WHERE grade<$1;
PREPARE
postgres=# explain analyze execute a1(70);
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Append (cost=0.00..40.12 rows=474 width=86) (actual time=0.012..0.012 rows=0 loops=1)
-> Seq Scan on stu_fail (cost=0.00..18.88 rows=237 width=86) (actual time=0.007..0.007 rows=0 loops=1)
Filter: (grade < 70)
-> Seq Scan on stu_pass (cost=0.00..18.88 rows=237 width=86) (actual time=0.001..0.001 rows=0 loops=1)
Filter: (grade < 70)
Planning Time: 1.636 ms
Execution Time: 0.128 ms
(7 rows)第二类,就是执行期间值可能动态发生变化,例如子查询可能查到多个值,因此在运行期间每次参数值更改时都将执行修剪。如果要排除分区,则该子计划的EXPLAIN输出中将显示(never executed)。
postgres=# explain analyze SELECT * FROM students WHERE id = (select 3);
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Append (cost=0.01..56.70 rows=12 width=86) (actual time=0.046..0.048 rows=1 loops=1)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.01 rows=1 width=4) (actual time=0.002..0.003 rows=1 loops=1)
-> Seq Scan on stu_part1 (cost=0.00..18.88 rows=4 width=86) (never executed)
Filter: (id = $0)
-> Seq Scan on stu_part2 (cost=0.00..18.88 rows=4 width=86) (actual time=0.026..0.028 rows=1 loops=1)
Filter: (id = $0)
-> Seq Scan on stu_part3 (cost=0.00..18.88 rows=4 width=86) (never executed)
Filter: (id = $0)
Planning Time: 0.387 ms
Execution Time: 0.125 ms
(11 rows)
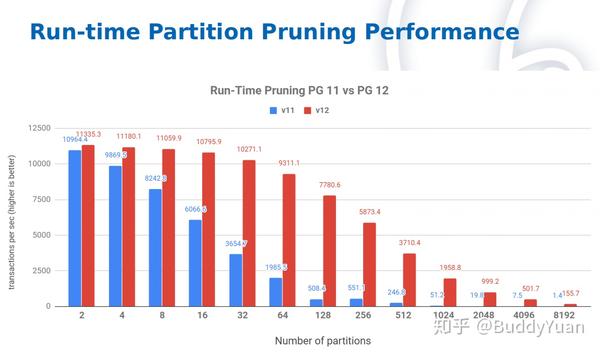
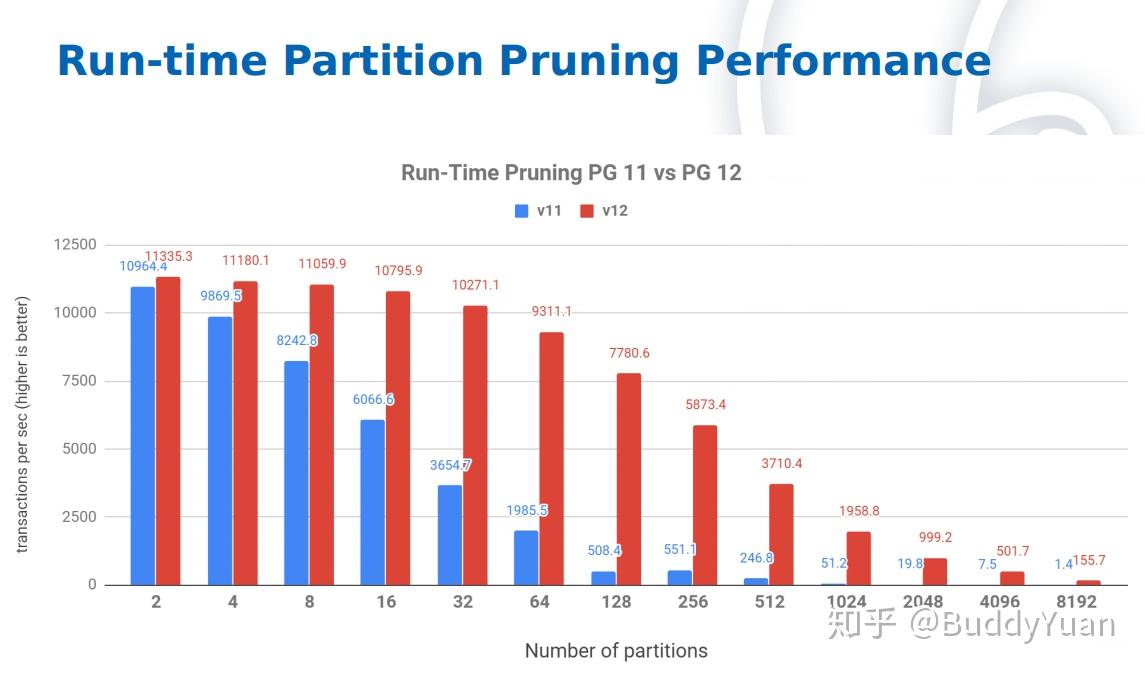
根据
2ndquadrant
提供的Run-time分区剪裁的基准测试结果,在分区数量少的情况下,PG12的性能要明显好于11,但是分区达到一定的数量之后,PG12的性能也会下降。
enable_partitionwise_join
允许查询优化器使用面向分区的连接,当分区表和分区表进行连接的时候,直接让分区和分区进行连接。面向分区的连接当前只适用于连接条件包括所有分区键的情况,连接条件必须是相同的数据类型并且子分区集合要完全匹配。由于面向分区的连接在规划期间会使用一些CPU Time和内存,所以默认值为off。
接下来我们来造点数据测试一下这个功能,分别创建a1和a2两张分区表,造300万数据。
CREATE TABLE a1 (a int primary key, b text) PARTITION BY RANGE (a);
CREATE TABLE a1_1 PARTITION OF a1 FOR VALUES FROM (1) TO (1000001);
CREATE TABLE a1_2 PARTITION OF a1 FOR VALUES FROM (1000001) TO (2000001);
CREATE TABLE a1_3 PARTITION OF a1 FOR VALUES FROM (2000001) TO (3000001);
CREATE TABLE a2 (c int primary key, d text) PARTITION BY RANGE (c);
CREATE TABLE a2_1 PARTITION OF a2 FOR VALUES FROM (1) TO (1000001);
CREATE TABLE a2_2 PARTITION OF a2 FOR VALUES FROM (1000001) TO (2000001);
CREATE TABLE a2_3 PARTITION OF a2 FOR VALUES FROM (2000001) TO (3000001);