BiGRU-Attention 模型
BiGRU-Attention 模型共分为三部分:
文本向量化输入层、 隐含层
和
输出层
。其中,隐含层由 BiGRU 层、attention 层和 Dense 层(全连接层)三层构成。BiGRU-Attention 模型结构如图 6 所示。
下面对这三层的功能分别进行介绍:
输入层即文本向量化输入层主要是对IMDB电影评论的25 000条数据的预处理。即把这些评论数据处理成 BiGRU 层能够直接接收并能处理的序列向量形式。m 个单词组成 l 个句子的文 本 a 即
 , 样 本 中 的 第 j 个句子表示为
, 样 本 中 的 第 j 个句子表示为
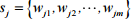 ,进行文本向量操作,使
,进行文本向量操作,使
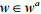 。文本向量化具体操作步骤如下:
。文本向量化具体操作步骤如下:
a)读取数据并进行数据清洗;
b)将数据向量化为规定长度 1 000 的形式(句子长度小于 规定值的,默认自动在后面填充特殊的符号;句子长度大于规定值的,默认保留前 1000 个,多余部分截去。)
c)随机初始化数据,按 8:2 划分训练集和测试集;
d)将数据向量化后,每一条电影评论都变成了统一长度的索引向量,每一个索引对应一个词向量。
经过上面的四步的操作之后,输入的 IMDB 数据就变成根据索引对应词向量的形成词矩阵,即设处理后词向量的统一长度为1000,使用 glove.6B.100d 的 100 维向量的形式,在 glove.6B.100d 中不能查找到的词向量随机初始化。设 cji 为第 j 个句子的第 i 个词向量,则一条长度为 1000 的 IMDB 评论数 据可以表示为:
其中:
 表示词向量与词向量的连接操作符,
表示为
表示词向量与词向量的连接操作符,
表示为
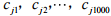 , , , 即为第 j 个句子的词向量矩阵。把 IMDB 每一条 评论中的每一个词按照索引去对应 glove.6B.100d 中词向量,生成词向量矩阵。
, , , 即为第 j 个句子的词向量矩阵。把 IMDB 每一条 评论中的每一个词按照索引去对应 glove.6B.100d 中词向量,生成词向量矩阵。
2
)隐含层
隐含层的计算主要分为两个步骤完成:
a)计算 BiGRU 层输出的词向量。文本词向量为 BiGRU 层 的输入向量。BiGRU 层的目的主要是对输入的文本向量进行文本深层次特征的提取。根据 BiGRU 神经网络模型图,可以把 BiGRU 模型看做由向前 GRU 和反向 GRU 两部分组成,在这 里简化为式(11)。在第 i 时刻输入的第 j 个句子的第 t 个单词的 词向量为
c
ijt ,通过 BiGRU 层特征提取后,可以更加充分地学习上下文之间的关系,进行语义编码,具体计算公式如式(11)所 示。
b)计算每个词向量应分配的概率权重。这个步骤主要是 为不同的词向量分配相应的概率权重,进一步提取文本特征,突 出文本的关键信息。在文本中,不同的词对文本情感分类起着 不同的作用。地点状语、时间状语对文本情感分类来说,重要程度极小;而具有情感色彩的形容词对文本情感分类却至关重要 。 为 了 突 出 不 同 词 对 整 个 文 本 情 感 分 类 的 重 要 度 , BiGRU-Attention 模型中引入了 attention 机制层。Attention 机制 层的输入为上一层中经过 BiGRU 神经网络层激活处理的输出 向量
h
ijt ,attention 机制层的权重系数具体通过以下几个公式进 行计算:
其中:
h
ijt 为上一层 BiGRU 神经网络层的输出向量, ww 表示权重 系数, bw 表示偏置系数,
u
w 表示随机初始化的注意力矩阵。 Attention 机制矩阵由 attention 机制分配的不同概率权重与各个隐层状态的乘积的累加和,使用 softmax 函数做归一化操作得 到。
输出层的输入为上一层 attention 机制层的输出。利用 softmax 函数对输出层的输入进行相应计算的方式从而进行文本分类,具体公式如下:
其中: w1 表示 attention 机制层到输出层的待训练的权重系数矩 阵, b 1 表示待训练相对应的偏置, y j 为输出的预测标签。
BiGRU-Attention 模型BiGRU-Attention 模型共分为三部分:文本向量化输入层、 隐含层和输出层。其中,隐含层由 BiGRU 层、attention 层和 Dense 层(全连接层)三层构成。BiGRU-Attention 模型结构如图 6 所示。下面对这三层的功能分别进行介绍:输入层 输入层即文本向量化输入层主要是对IMDB电影评论的25 000条...
但是这种方式是基于RNN
模型
,存在两个问题。
一是RNN存在梯度消失的问题。(LSTM/GRU只是缓解这个问题)
二是RNN 有时间上的方向性,不能用于并行操作。Transformer 摆脱了RNN这种问题。
2.Transformer 的整体框架
输入的x1,x2x_{1},x_{2}x1,x2,共同经过Self-
attention
机制后,在Self-
attention
中实现了信息的交互,分别得到了z1,z2z_{1},z_{2}z1,z2,将z1,z2
3、相关技术
相比LSTM,使用GRU能够达到相当的效果,准确率不会差多少,并且相比之下GRU更容易进行训练,能够很大程度上提高训练效率,因此硬件资源有限时会更倾向于使用GRU。
GRU结构图如下:
4、完整代码和步骤
此代码的依赖环境如下:
tensorflow==2.5.0
numpy==1.19.5
keras==2.6.0
matplotlib==3.5.2
————————————————
版权声明:本文为CSDN博主「AI信仰者」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_30803353/article/details/129108978
提出了一种基于
Attention
机制的卷积神经网络(convolutional
neural network,CNN)-GRU (gated recurrent unit)短期电力负荷
预测方法,该方法将历史负荷数据作为输入,搭建由一维卷
积层和池化层等组成的 CNN 架构,提取反映负荷复杂动态变
化的高维特征;将所提特征向量构造为时间序列形式作为
GRU 网络的输入,建模学习特征内部动态变化规律,并引入
Attention
机制通过映射加权和学习参数矩阵赋予 GRU 隐含
[-0.058550 0.125846 -0.083195 0.031818 -0.183519…], —>’,’
[0.087197 -0.083435 0.057956 0.143120 -0.000068…], ---->‘的’
每一行都是一个词的向量,最后两行是随机生成的正态分布数据,对应下面的UNK和BLA...
本项目将演示如何从用户提供的快递单中,抽取姓名、电话、省、市、区、详细地址等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。
此外,通过从快递单抽取信息这个任务,介绍序列化标注
模型
及其在 Paddle 的使用方式。
本项目基于PaddleNLP NER example的代码进行修改,主要包括“背景介绍”、“代码实践”、“进阶使用”、“概念解释”等四个部分。
主要介绍:
PaddleN
目录Self-
Attention
的结构图forward输入中的query、key、valueforward的输出实例化一个nn.Multihead
Attention
进行forward操作关于maskReference
Self-
Attention
的结构图
本文侧重于Pytorch中对self-
attention
的具体实践,具体原理不作大量说明,self-
attention
的具体结构请参照下图。
(图中为输出第二项
attention
output的情况,k与q为key、query的缩写)
本文中将使用Pyt
### 回答1:
CNN-
BiGRU
-
Attention
是一种
深度学习
模型
,它结合了卷积神经网络(CNN)、双向门控循环单元(
BiGRU
)和注意力机制(
Attention
)。该
模型
主要用于
自然语言处理
任务,如文本分类、情感分析等。CNN-
BiGRU
-
Attention
模型
可以有效地提取文本中的特征,并且能够自动关注文本中的重要信息,从而提高
模型
的性能。
### 回答2:
CNN-
BiGRU
-
Attention
是一种基于卷积神经网络(CNN)、双向门控循环单元(
BiGRU
)和注意力机制(
Attention
)的
深度学习
模型
,用于解决
自然语言处理
任务中的文本分类、情感分析等问题。
CNN是区分局部特征的一种卷积神经网络
模型
,可以提取文本中的各种特征,包括语义、语法和句法等。
BiGRU
是一种门控循环单元
模型
,可以通过学习上下文信息提高文本分类精度。而
Attention
则可以通过加权思想来实现对不同部分特征的加权重要性,并逐个区分文本中各个词汇的重要程度。
采用CNN-
BiGRU
-
Attention
模型
相对于单一卷积神经网络
模型
,更加能够理解语义,更完整地捕获文本的所有特征,不同部分相互协作,提取了更加全面且包含了更多语法信息的文本表示,这也更具有解释性。同时该
模型
对于长文本尤为适用,能够更好地维护上下文特征。此外,
模型
的出现也解决了在过去
深度学习
中长文本情况下,易受梯度消失、梯度弥散的问题。
在实际应用中,该
模型
可以适用于分类、情感分析、机器翻译等任务,使得算法
模型
更加优秀和准确,提高了我们解决NLP问题的能力。由此看来,CNN-
BiGRU
-
Attention
是一种潜力巨大、提高效果显著的技术,有望推动
自然语言处理
任务到更深更广的方向发展。
### 回答3:
CNN-
BiGRU
-
Attention
模型
是一种在文本分类任务上表现良好的
深度学习
模型
。这个
模型
的架构包括了卷积神经网络(CNN)、双向长短期记忆网络(
BiGRU
)以及注意力机制(
Attention
)。
在这个
模型
中,首先,输入的文本数据被送入卷积神经网络中进行卷积和池化操作,目的是提取文本中的局部特征。然后,这些局部特征被送入双向长短期记忆网络中进行序列建模,以便学习上下文信息。接着,通过使用注意力机制,可以将不同的局部特征加权,以便更好地捕捉关键信息。最后,将这些加权结果送入全连接层中,进行最终的分类。
几个关键的技术点可以使得CNN-
BiGRU
-
Attention
模型
在文本分类任务中表现优异。首先,卷积神经网络可以有效地提取局部特征。双向长短期记忆网络则可以捕捉上下文信息,即文本中前后信息的依赖性。在使用注意力机制后,可以更好地关注文本中的重要信息,避免过多关注无用信息。最后,全连接层可以进行分类。
总之,CNN-
BiGRU
-
Attention
模型
的优点在于其能够组合不同技术来提取文本中的重要信息,以及在处理上下文信息时表现较好,因此是一种较为有效的文本分类
模型
。

