

CNN中注意力机制(PyTorch实现SE、ECA、CBAM)

什么叫注意力机制?
注意力机制顾名思义就是通过对感兴趣的区域提升更多的注意力,尽可能的抑制不感兴趣的区域在图像分割中的作用。深度学习CNN中可以将注意力机制分为通道注意力和空间注意力两种,通道注意力是确定不同通道之间的权重关系,提升重点通道的权重,抑制作用不大的通道,空间注意力是确定空间邻域不同像素之间的权重关系,提升重点区域像素的权重,让算法更多的关注我们需要的研究区域,减小非必要区域的权重。
一、SE (Squeeze and Excitation)注意力机制
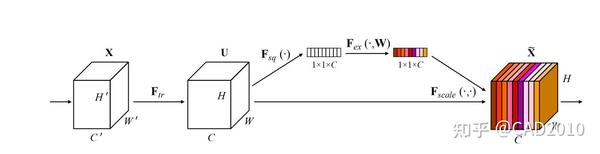
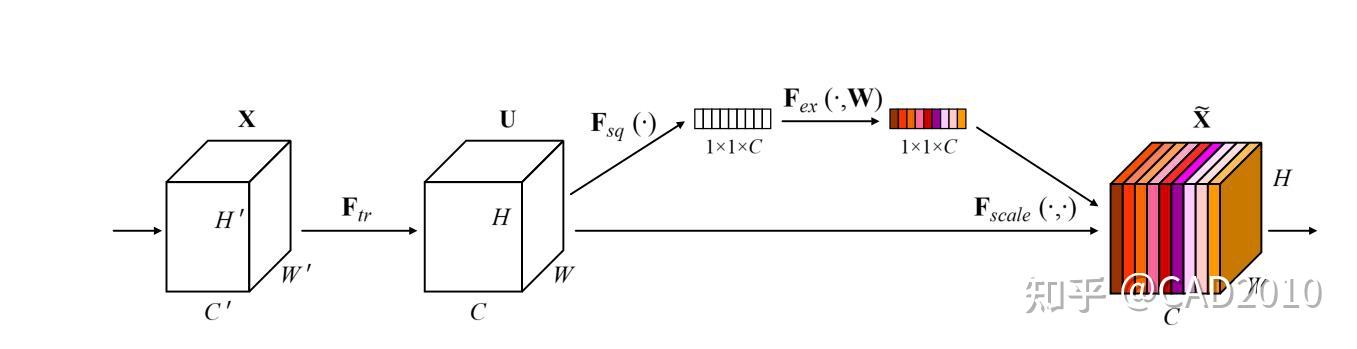
SE注意力机制是通道注意力模式下的一种确定权重的方法,它通过在不同通道间分配权重达到主次优先的目的。如下图所示,为SE注意力机制的结构图。
该结构主要分为以下三个方面:
①:通过将特征图进行Squeeze(压缩),该步骤是通过全局平均池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合。
②:Excitation操作,该步骤使用两个全连接层,通过全连接层之间的非线性添加模型的复杂度,达到确定不同通道之间的权重作用,其中第一个全连接层使用ReLU激活函数,第二个全连接层采用Sigmoid激活函数,为了将权重中映射到(0,1)之间。值得注意的是,为了减少计算量进行降维处理,将第一个全连接的输出采用输入的1/4或者1/16。
③:将reshape过后的权重值与原有的特征图做乘法运算(该步骤采用了Python的广播机制),得到不同权重下的特征图。
具体PyTorch实现代码如下:
import torch
import torch.nn as nn
class Se(nn.Module):
def __init__(self,in_channel,reduction=16):
super(Se, self).__init__()
self.pool=nn.AdaptiveAvgPool2d(output_size=1)
self.fc=nn.Sequential(
nn.Linear(in_features=in_channel,out_features=in_channel//reduction,bias=False),
nn.ReLU(),
nn.Linear(in_features=in_channel//reduction,out_features=in_channel,bias=False),
nn.Sigmoid()
def forward(self,x):
out=self.pool(x)
out=self.fc(out.view(out.size(0),-1))
out=out.view(x.size(0),x.size(1),1,1)
return out*x二、ECA(Efficient Channel Attention)
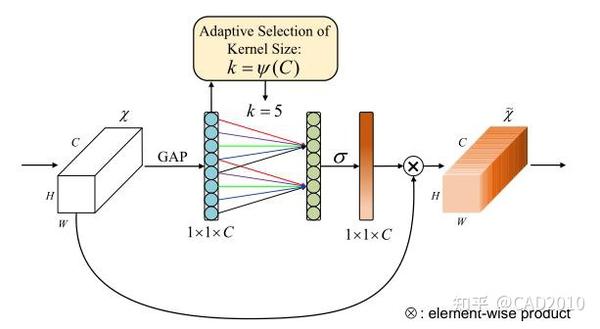
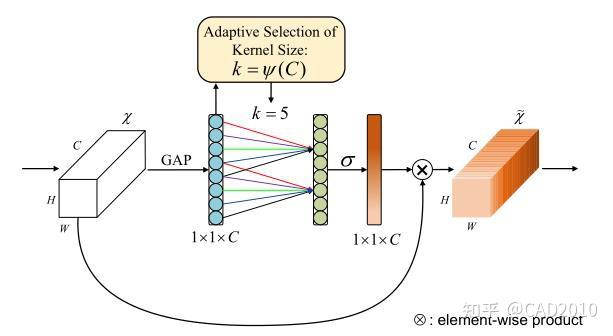
ECA注意力机制也是通道注意力的一种方法,该算法是在SE算法的基础上做出了一定的改进,首先ECA作者认为SE虽然全连接的降维可以降低模型的复杂度,但是破坏了通道与其权重之间的直接对应关系,先降维后升维,这样权重和通道的对应关系是间接的,基于上述,作者提出一维卷积的方法,避免了降维对数据的影响。
该结构主要分为以下三个方面:
①:通过将特征图进行Squeeze(压缩),该步骤是通过全局平均池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合,该步骤和SE一样。
②:计算自适应卷积核的大小, k=\left| \frac{log_{2}(C)}{\gamma} +\frac{b}{\gamma}\right| ,其中C为输入的通道数,b=1, \gamma =2,并采用一维卷积计算通道的权重,最后采用Sigmoid激活函数将权重映射在(0-1)之间。
③:将reshape过后的权重值与原有的特征图做乘法运算(该步骤采用了Python的广播机制),得到不同权重下的特征图。
具体PyTorch实现代码如下:
import torch
import torch.nn as nn
import math
class ECA(nn.Module):
def __init__(self,in_channel,gamma=2,b=1):
super(ECA, self).__init__()
k=int(abs((math.log(in_channel,2)+b)/gamma))
kernel_size=k if k % 2 else k+1
padding=kernel_size//2
self.pool=nn.AdaptiveAvgPool2d(output_size=1)
self.conv=nn.Sequential(
nn.Conv1d(in_channels=1,out_channels=1,kernel_size=kernel_size,padding=padding,bias=False),
nn.Sigmoid()
def forward(self,x):
out=self.pool(x)
out=out.view(x.size(0),1,x.size(1))
out=self.conv(out)
out=out.view(x.size(0),x.size(1),1,1)
return out*x三、CBAM(Convolutional Block Attention Module)
CBAM注意力机制是一种将通道与空间注意力机制相结合的算法模型,算法整体结构如图3所示,输入特征图先进行通道注意力机制再进行空间注意力机制操作,最后输出,这样从通道和空间两个方面达到了强化感兴趣区域的目的。
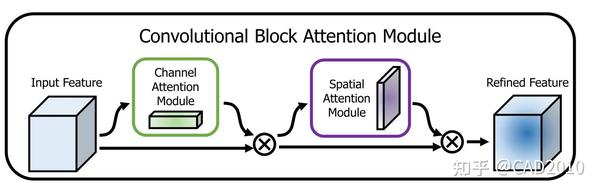
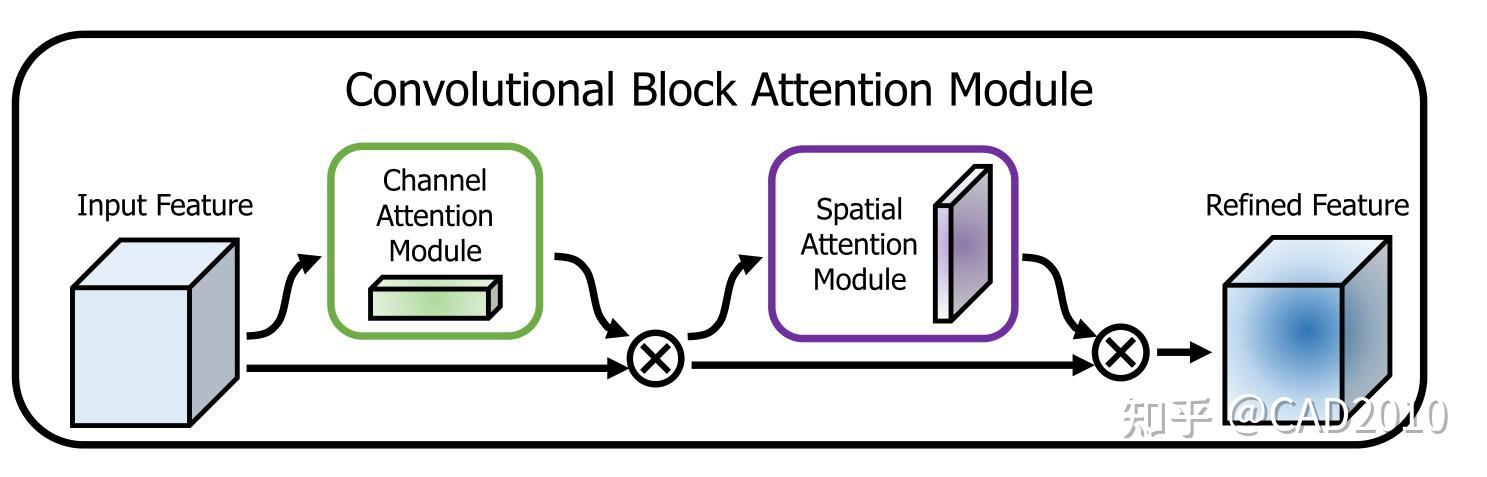
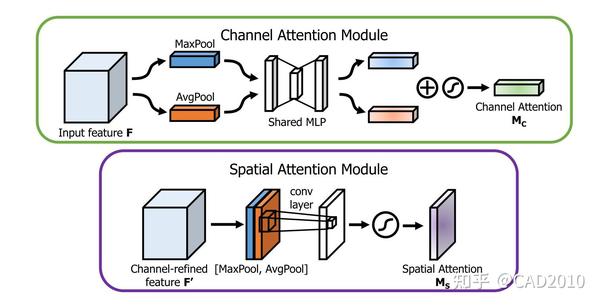
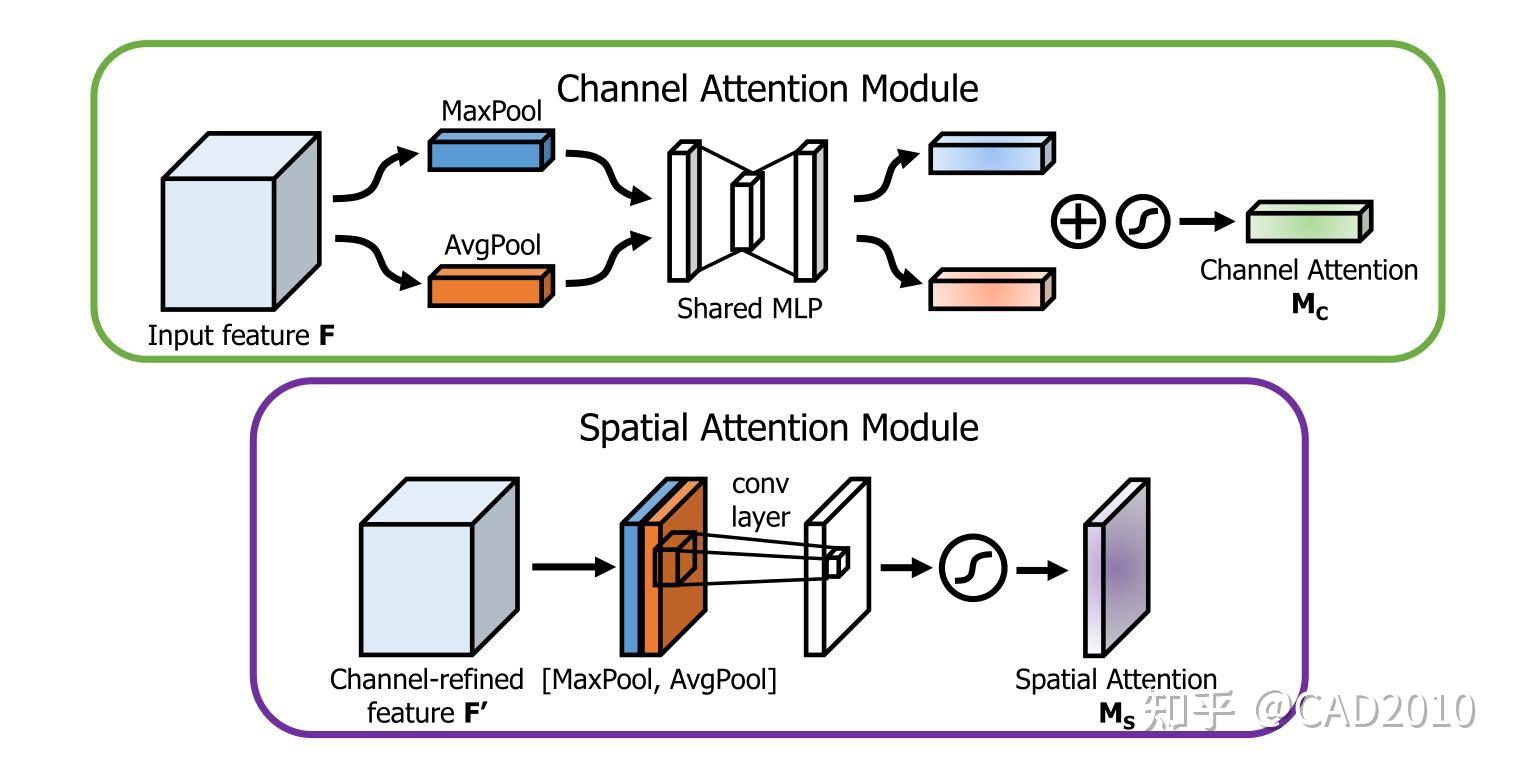
通道结构主要分为以下三个方面:
①:通过将特征图进行Squeeze(压缩),该步骤分别采用全局平均池化和全局最大池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合。
②:分别将全局最大池化和全局平均池化结果进行MLP(多层感知机)操作,MLP在这里定义与SE的操作一样,为两层全连接层,中间采用ReLU激活,最后将两者相加后利用Sigmoid函数激活。
③:将reshape过后的权重值与原有的特征图做乘法运算(该步骤采用了Python的广播机制),得到不同权重下的特征图。
空间结构主要分为以下三个方面:
①:将上述通道注意力操作的结果,分别在通道维度上进行最大池化和平均池化,即将经过通道注意力机制的特征图从(N,C,H,W)转换为(N,1,H,W),达到融合不同通道的信息的效果,然后在通道维度上将最大池化与平均池化结果叠加起来,即采用torch.cat()。
②:将叠加后2个通道的结果做卷积运算,输出通道为1,卷积核大小为7,最后将输出结果采用Sigmoid函数激活。
③:将权重值与原有的特征图做乘法运算(该步骤采用了Python的广播机制),得到不同权重下的特征图。
import torch
import torch.nn as nn
import math
class CBAM(nn.Module):
def __init__(self,in_channel,reduction=16,kernel_size=7):
super(CBAM, self).__init__()
#通道注意力机制
self.max_pool=nn.AdaptiveMaxPool2d(output_size=1)
self.avg_pool=nn.AdaptiveAvgPool2d(output_size=1)
self.mlp=nn.Sequential(
nn.Linear(in_features=in_channel,out_features=in_channel//reduction,bias=False),
nn.ReLU(),
nn.Linear(in_features=in_channel//reduction,out_features=in_channel,bias=False)
self.sigmoid=nn.Sigmoid()
#空间注意力机制
self.conv=nn.Conv2d(in_channels=2,out_channels=1,kernel_size=kernel_size ,stride=1,padding=kernel_size//2,bias=False)
def forward(self,x):
#通道注意力机制
maxout=self.max_pool(x)
maxout=self.mlp(maxout.view(maxout.size(0),-1))
avgout=self.avg_pool(x)
avgout=self.mlp(avgout.view(avgout.size(0),-1))
channel_out=self.sigmoid(maxout+avgout)
channel_out=channel_out.view(x.size(0),x.size(1),1,1)
channel_out=channel_out*x
#空间注意力机制