

Redis做MySQL的缓存是怎么做的?
关注者
7
被浏览
8,393
5 个回答

1、缓存是什么
缓存就是数据交换的缓冲,是存贮数据的临时地方,一般读写性能较高。
常见的缓存有浏览器缓存、应用层缓存、数据库缓存、CPU缓存、磁盘缓存等等。
缓存的作用:
- 降低后端负载
- 提高读写效率,降低响应时间
缓存的成本:
- 数据一致性成本
- 代码维护成本
- 运维成本
2、为项目添加redis缓存
添加redis缓存模型如下:
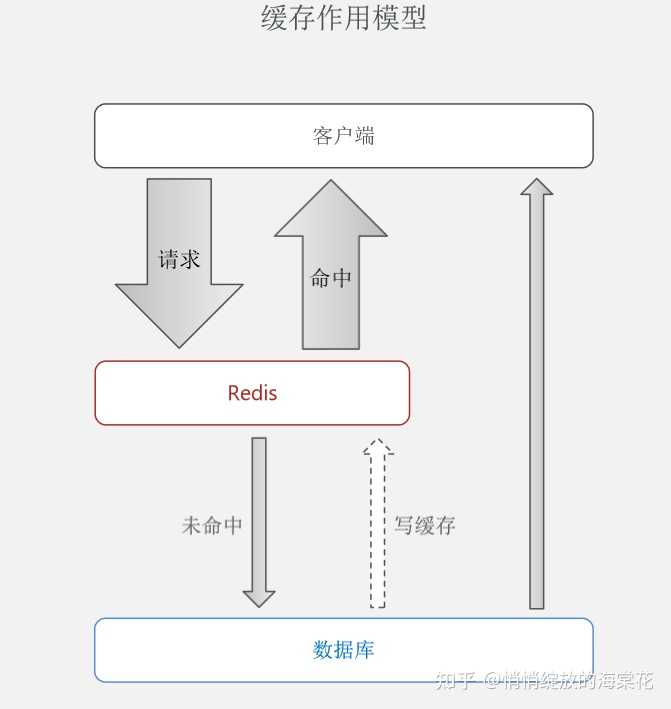
模型流程:
客户端向后台服务器发送请求,查询需要的数据在redis中是否存在?
- 当数据存在时,直接将命中数据返回即可。
- 当需要的数据在redis中不存在时,查询数据库,查询成功之后现将查询到的数据写入redis中,然后将查询到的数据返回给客户端。
根据id查询商铺信息的流程图如图所示:
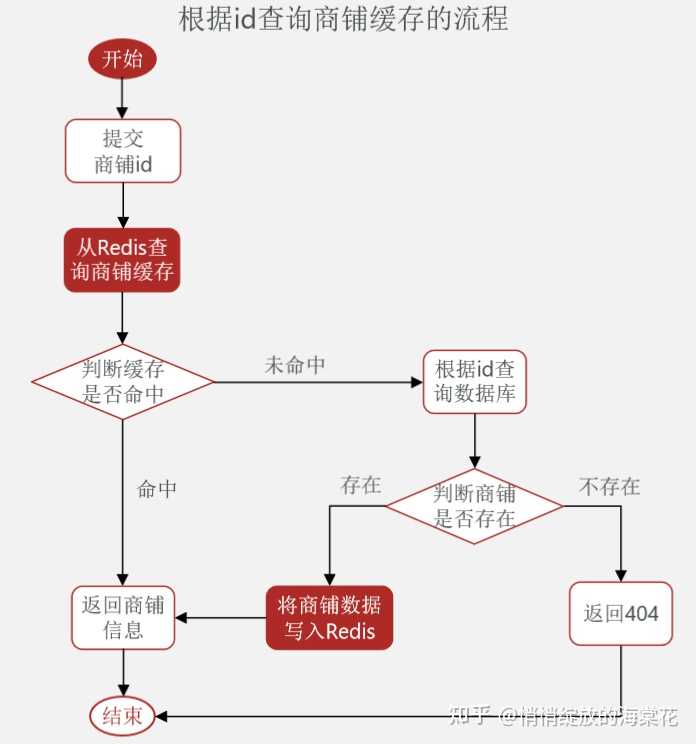
3、缓存更新策略
常见 缓存更新策略有 内存淘汰、超时剔除和主动更新
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不用自己维护,利用Redis点的内存淘汰机制,当内存不足时自动淘汰部分数据,下次查询时更新缓存 | 给缓存添加TTL时间,到期后自动删除缓存,下次查询时自动更新缓存 | 编写业务逻辑时,在修改数据库的同时,更新缓存 |
| 一致性 | 查 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
业务场景: 低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存 高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存
我们一般使用在更新数据库的同时更新缓存
操作缓存和数据库时有三个问题需要考虑:
1、删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存(更优)
2、如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
3、先操作缓存还是先操作数据库?
- 先删除缓存,再操作数据库
- 先操作数据库,再删除缓存(更优)
针对先操作缓存还是先操作数据库这里做出详细说明?
1、先操作缓存,再操作数据库
原始在数据库中有 v = 10,缓存中有 v = 10;
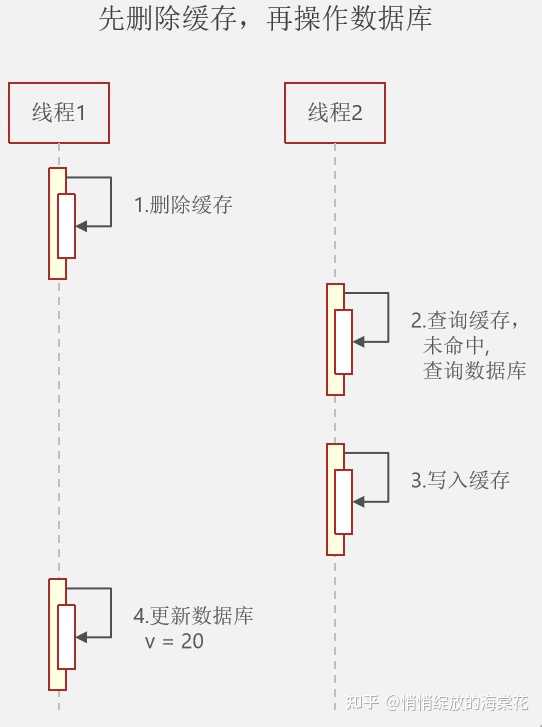
说明:如上图所示,线程1需要将缓存中的 v = 10 修改为 v = 20,线程2查询数据库中的 v 的值;线程1首先到达,执行图中的 步骤1 删除了缓存中的数据,这是线程2也来了,执行 步骤2 ,缓存中的数据已经被线程1删除了,所以未命中数据,就查询数据库,查询成功以后执行 步骤3 ,然后又将数据库中的 v = 10 写入到了缓存,这是线程1才执行 步骤4 将数据库中的数据更新为 v = 20,这是就会出现缓存中为 v = 10而数据库中 v = 20 的情况,出现了数据库与缓存数据不一致。
对于以上情况出现的可能性还是非常大的 ,因为对于线程2,执行 步骤2 和 步骤3 只是操作缓存和查询了一下数据库,用时相对时非常少的,对于线程1,当执行了 步骤1 之后,若需要更新的数据更新非常复杂,需要用到的时间相对来说就会比较久了, 步骤1 和 步骤4 之间的时间就大一些,很可能大于 步骤2 和 步骤3 的总时间,所以先删除缓存再更新数据库出现数据不一致的情况可能性是非常大的。
2、先操作数据库,再操作数缓存
原始在数据库中有 v = 10,缓存中不存在 v
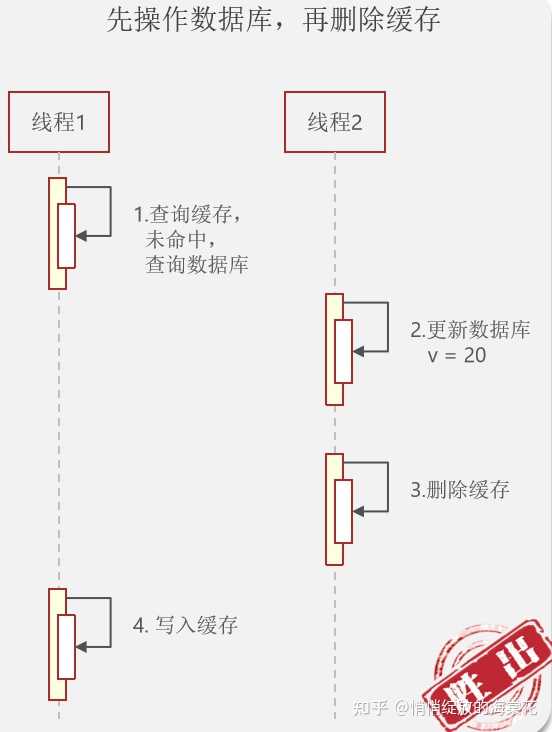
说明:如上图所示,线程1需要查询数据库中的 v值,线程2需要将数据库中的v = 10修改为 v = 20;线程1首先到达,执行 步骤1 查询缓存中是否存在 v 的值,没有查到,就查询数据库得到 v = 10,恰恰这是,线程2到了,执行 步骤2 将数据库中的 v 修改为 v = 20,之后执行 步骤3 ,将缓存中的 v = 10 删除,这是线程1才执行 步骤 4 ,将步骤1得到的 v = 10 写入到缓存。这是就是缓存中 v = 10,数据库中 v = 20,出现数据不一致了。
对于以上情况出现的可能性还是非常小的 ,因为对于线程2,执行 步骤2 和 步骤3 需要更新数据库,假如获取更新后的数据更新非常复杂,需要用到的时间相对来说就会比较久了,对于线程1,当执行了 步骤1 之后, 只是操作缓存和查询了一下数据库,用时相对时非常少的,开始 步骤1 和开始 步骤4 之间的时间就小很多,基本上远远小于 步骤2 和 步骤3 的总时间,所以先更新数据库再删除缓存再出现数据不一致的情况可能性就非常小了。
所以在实际项目开发过程中,我们的选择实现先更新数据库然后在删除缓存是比较好的方案
