

随着时间的积累,日志数据会越来越多,当您需要查看并分析庞杂的日志数据时,可通过Filebeat+Kafka+Logstash+Elasticsearch采集日志数据到阿里云Elasticsearch中,并通过Kibana进行可视化展示与分析。本文介绍具体的实现方法。
背景信息
Kafka是一种分布式、高吞吐、可扩展的消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,已成为大数据生态中不可或缺的部分。更多信息,请参见 什么是云消息队列 Kafka 版 。
在实际应用场景中,为了满足大数据实时检索的需求,您可以使用Filebeat采集日志数据,并输出到Kafka中。Kafka实时接收Filebeat采集的数据,并输出到Logstash中。输出到Logstash中的数据在格式或内容上可能不能满足您的需求,此时可以通过Logstash的filter插件过滤数据。最后将满足需求的数据输出到Elasticsearch中进行分布式检索,并通过Kibana进行数据分析与展示。简单流程如下。

操作流程
-
完成环境准备,包括创建阿里云Elasticsearch、Logstash、ECS和
云消息队列 Kafka 版实例、创建Topic和Consumer Group等。
重要建议您使用同一专有网络VPC(Virtual Private Cloud)下的阿里云Elasticsearch、Logstash、ECS和
云消息队列 Kafka 版实例。
-
安装并配置Filebeat,设置input为系统日志,output为Kafka,将日志数据采集到Kafka的指定Topic中。
-
配置Logstash管道的input为Kafka,output为阿里云Elasticsearch,使用Logstash消费Topic中的数据并传输到阿里云Elasticsearch中。
-
在消息队列Kafka中查看日志数据的消费的状态,验证日志数据是否采集成功。
-
在Kibana控制台的Discover页面,通过Filter过滤出Kafka相关的日志。
准备工作
-
创建阿里云Elasticsearch实例,并开启实例的自动创建索引功能。
具体操作步骤请参见 创建阿里云Elasticsearch实例 和 配置YML参数 。本文以6.7版本为例。
-
创建阿里云Logstash实例。
具体操作步骤请参见 创建阿里云Logstash实例 。创建的实例需要满足:
-
版本:与阿里云Elasticsearch实例的版本要满足兼容性要求,详细信息请参见 产品兼容性 。本文使用与Elasticsearch相同的版本,即6.7版本。
-
网络:与阿里云Elasticsearch实例在同一VPC下,否则需要配置NAT网关实现与公网的连通,详细信息请参见 配置NAT公网数据传输 。
-
-
购买并部署阿里云
云消息队列 Kafka 版实例、创建Topic和Consumer Group。
-
创建阿里云ECS实例。
具体操作步骤请参见 自定义购买实例 。本文的ECS实例与阿里云Elasticsearch实例在同一VPC下,否则需要配置公网访问白名单实现网络互通,详细信息请参见 配置实例公网或私网访问白名单 。
重要该ECS实例用来安装Filebeat,由于Filebeat目前仅支持Aliyun Linux、RedHat和CentOS这三种操作系统,因此在创建时请选择其中一种操作系统。
步骤一:安装并配置Filebeat
-
连接ECS服务器。
具体操作步骤请参见 连接实例 。
-
安装Filebeat。
本文以 6.8.5版本 为例,安装命令如下,详细信息请参见 Install Filebeat 。
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.8.5-linux-x86_64.tar.gz tar xzvf filebeat-6.8.5-linux-x86_64.tar.gz -
执行以下命令,进入Filebeat安装目录,创建并配置filebeat.kafka.yml文件。
cd filebeat-6.8.5-linux-x86_64 vi filebeat.kafka.ymlfilebeat.kafka.yml配置如下。
filebeat.prospectors: - type: log enabled: true paths: - /var/log/*.log output.kafka: hosts: ["alikafka-post-cn-zvp2n4v7****-1-vpc.alikafka.aliyuncs.com:9092"] topic: estest version: 0.10.2重要当Filebeat为7.0及以上版本时, filebeat.prospectors 需要替换为 filebeat.inputs 。
参数
说明
type
输入类型。设置为log,表示输入源为日志。
enabled
设置配置是否生效:
-
true:生效
-
false:不生效
paths
需要监控的日志文件的路径。多个日志可在当前路径下另起一行写入日志文件路径。
hosts
消息队列Kafka实例的单个接入点,可在实例详情页面获取,详情请参见 查看接入点 。由于本文使用的是VPC实例,因此使用默认接入点中的任意一个接入点。
topic
日志输出到消息队列Kafka的Topic,请指定为您已创建的Topic。
version
Kafka的版本,可在消息队列Kafka的实例详情页面获取。
重要-
不配置此参数会报错。
-
由于不同版本的Filebeat支持的Kafka版本不同,例如8.2及以上版本的Filebeat支持的Kafka版本为2.2.0,因此 version 需要设置为Filebeat支持的Kafka版本,否则会出现类似报错:
Exiting: error initializing publisher: unknown/unsupported kafka vesion '2.2.0' accessing 'output.kafka.version' (source:'filebeat.kafka.yml'),详细信息请参见 version 。
-
-
启动Filebeat。
./filebeat -e -c filebeat.kafka.yml
步骤二:配置Logstash管道
- 进入 阿里云Elasticsearch控制台的Logstash页面 。
-
进入目标实例。
- 在顶部菜单栏处,选择地域。
- 在 Logstash实例 中单击目标实例ID。
-
在左侧导航栏,单击 管道管理 。
-
单击 创建管道 。
-
在 创建管道任务 页面,输入 管道ID 并配置管道。
本文使用的管道配置如下。
input { kafka { bootstrap_servers => ["alikafka-post-cn-zvp2n4v7****-1-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-2-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-3-vpc.alikafka.aliyuncs.com:9092"] group_id => "es-test" topics => ["estest"] codec => json filter { output { elasticsearch { hosts => "http://es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com:9200" user =>"elastic" password =>"<your_password>" index => "kafka‐%{+YYYY.MM.dd}" }表 1. input参数说明 参数
说明
bootstrap_servers
消息队列Kafka实例的接入点,可在实例详情页面获取,详情请参见 查看接入点 。由于本文使用的是VPC实例,因此使用默认接入点。
group_id
指定为您已创建的Consumer Group的名称。
topics
指定为您已创建的Topic的名称,需要与Filebeat中配置的Topic名称保持一致。
codec
设置为 json ,表示解析JSON格式的字段,便于在Kibana中分析。
表 2. output参数说明 参数
说明
hosts
阿里云Elasticsearch的访问地址,取值为
http://<阿里云Elasticsearch实例的私网地址>:9200。说明您可在阿里云Elasticsearch实例的基本信息页面获取其私网地址,详情请参见 查看实例的基本信息 。
user
访问阿里云Elasticsearch的用户名,默认为elastic。您也可以使用自建用户,详情请参见 通过Elasticsearch X-Pack角色管理实现用户权限管控 。
password
访问阿里云Elasticsearch的密码,在创建实例时设置。如果忘记密码,可进行重置,重置密码的注意事项及操作步骤请参见 重置实例访问密码 。
index
索引名称。设置为
kafka‐%{+YYYY.MM.dd}表示索引名称以kafka为前缀,以日期为后缀,例如kafka-2020.05.27。更多Config配置详情请参见 Logstash配置文件说明 。
如果您有多topic的数据同步需求,需要在kafka中添加新的topic,然后在Logstash的管道配置中添加input。示例如下:
input { kafka { bootstrap_servers => ["alikafka-post-cn-zvp2n4v7****-1-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-2-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-3-vpc.alikafka.aliyuncs.com:9092"] group_id => "es-test" topics => ["estest"] codec => json kafka { bootstrap_servers => ["alikafka-post-cn-zvp2n4v7****-1-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-2-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-3-vpc.alikafka.aliyuncs.com:9092"] group_id => "es-test-2" topics => ["estest_2"] codec => json } -
单击 下一步 ,配置管道参数。
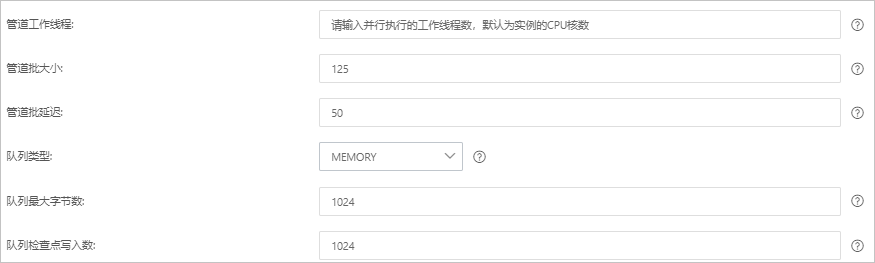
参数
说明
管道工作线程
并行执行管道的Filter和Output的工作线程数量。当事件出现积压或CPU未饱和时,请考虑增大线程数,更好地使用CPU处理能力。默认值:实例的CPU核数。
管道批大小
单个工作线程在尝试执行Filter和Output前,可以从Input收集的最大事件数目。较大的管道批大小可能会带来较大的内存开销。您可以设置LS_HEAP_SIZE变量,来增大JVM堆大小,从而有效使用该值。默认值:125。
管道批延迟
创建管道事件批时,将过小的批分派给管道工作线程之前,要等候每个事件的时长,单位为毫秒。默认值:50ms。
队列类型
用于事件缓冲的内部排队模型。可选值:
-
MEMORY :默认值。基于内存的传统队列。
-
PERSISTED :基于磁盘的ACKed队列(持久队列)。
队列最大字节数
请确保该值小于您的磁盘总容量。默认值:1024 MB。
队列检查点写入数
启用持久性队列时,在强制执行检查点之前已写入事件的最大数目。设置为0,表示无限制。默认值:1024。
警告配置完成后,需要保存并部署才能生效。保存并部署操作会触发实例重启,请在不影响业务的前提下,继续执行以下步骤。
-
-
单击 保存 或者 保存并部署 。
-
保存 :将管道信息保存在Logstash里并触发实例变更,配置不会生效。保存后,系统会返回 管道管理 页面。可在 管道列表 区域,单击 操作 列下的 立即部署 ,触发实例重启,使配置生效。
-
保存并部署 :保存并且部署后,会触发实例重启,使配置生效。
-
步骤三:查看日志消费状态
-
进入 消息队列Kafka控制台 。
-
参见 查看消费状态 ,查看详细消费状态。
预期结果如下:

步骤四:通过Kibana过滤日志数据
-
登录目标阿里云Elasticsearch实例的Kibana控制台,根据页面提示进入Kibana主页。
登录Kibana控制台的具体操作,请参见 登录Kibana控制台 。说明 本文以阿里云Elasticsearch 6.7.0版本为例,其他版本操作可能略有差别,请以实际界面为准。
-
创建一个索引模式。
-
在左侧导航栏,单击 Management 。
-
在Kibana区域,单击 Index Patterns 。
-
单击 Create index pattern 。
-
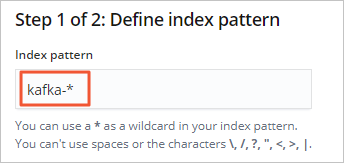
输入 Index pattern (本文使用kafka-*),单击 Next step 。
-
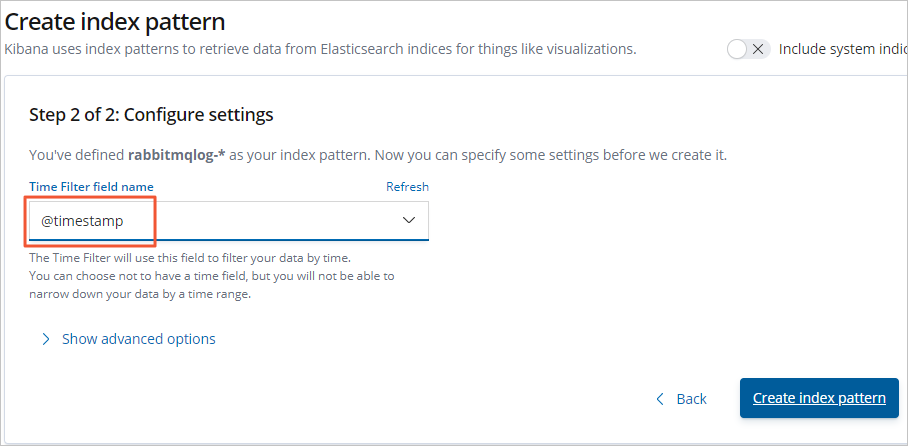
选择 Time Filter field name (本文选择 @timestamp ),单击 Create index pattern 。
-
-
在左侧导航栏,单击 Discover 。
-
从页面左侧的下拉列表中,选择您已创建的索引模式(kafka-*)。
-
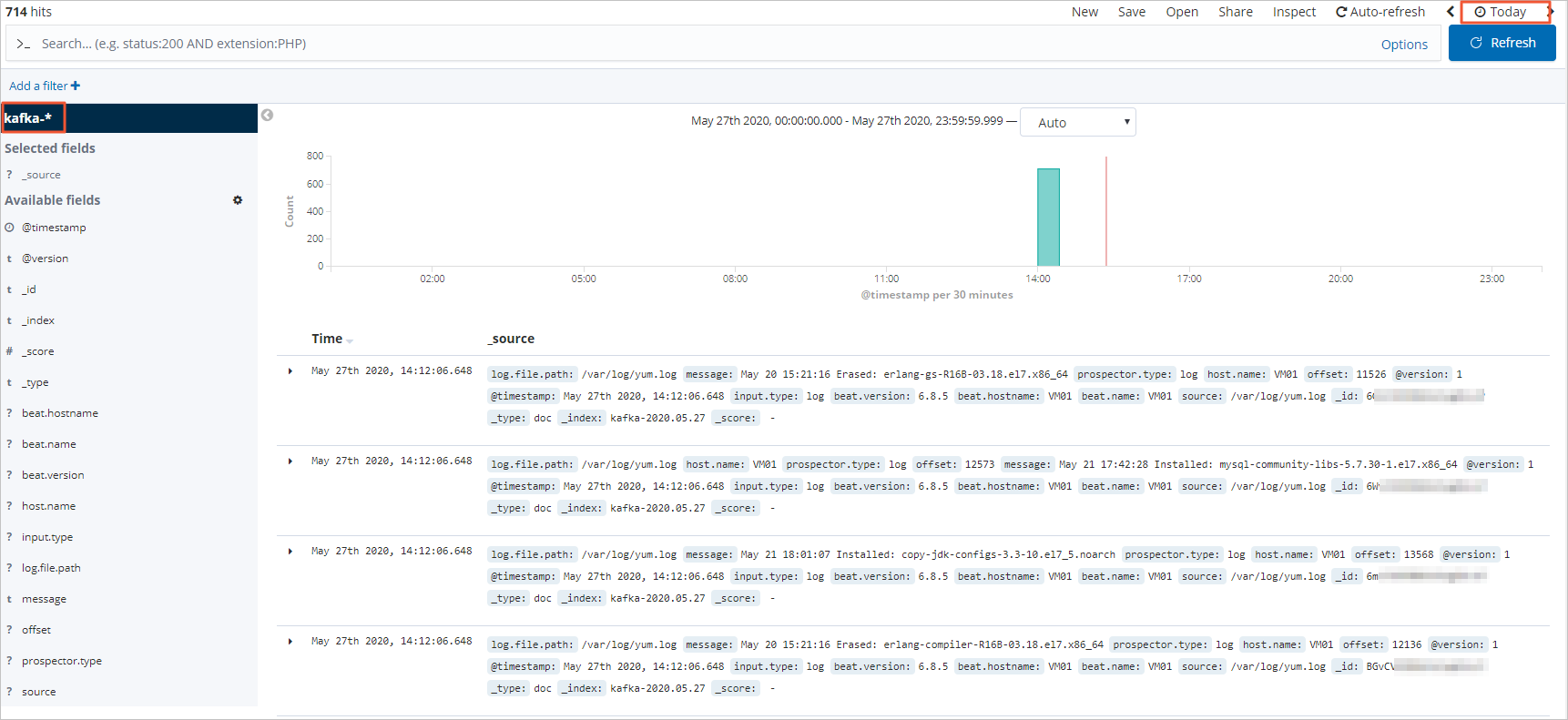
在页面右上角,选择一段时间,查看对应时间段内的Filebeat采集的日志数据。
-
单击 Add a filter ,在 Add filter 页面中设置过滤条件,查看符合对应过滤条件的日志数据。
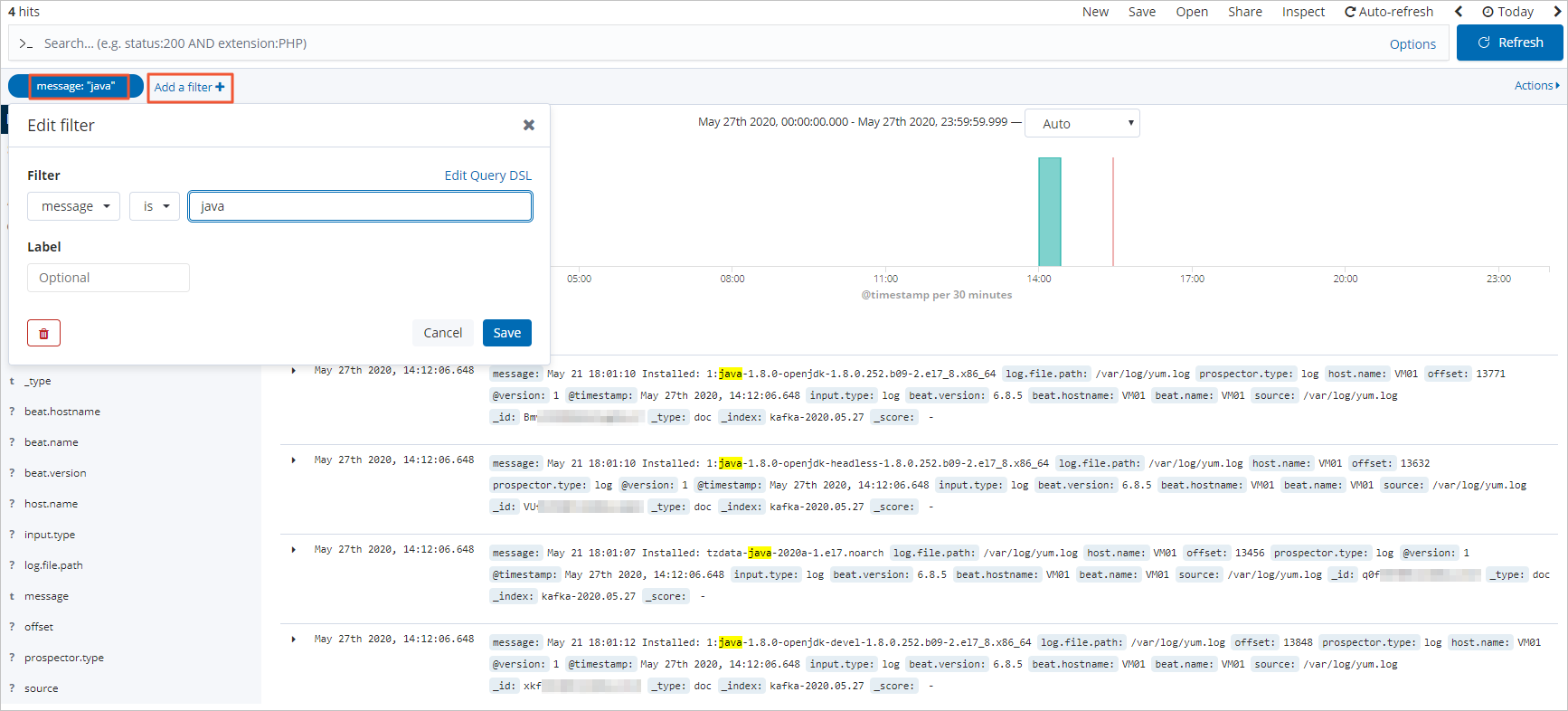
常见问题
Q:同步日志数据出现问题,管道一直在生效中,无法将数据导入Elasticsearch,如何解决?
A:查看Logstash实例的主日志是否有报错,根据报错判断原因,具体操作请参见 查询日志 。常见的原因及解决方法如下。
|
原因 |
解决方法 |
|
Kafka的接入点不正确。 |
参见 查看接入点 获取正确的接入点。完成后,修改管道配置替换错误接入点。 |
|
Logstash与Kafka不在同一VPC下。 |
重新购买同一VPC下的实例。购买后,修改现有管道配置。
说明
VPC实例只能通过专有网络VPC访问 云消息队列 Kafka 版。 |
|
Kafka或Logstash集群的配置太低,例如使用了测试版集群。 |
升级集群规格,完成后,刷新实例,观察变更进度。升级Logstash实例规格的具体操作,请参见 升配集群 ;升级Kafka实例规格的具体操作,请参见 升级实例配置 。 |
|
管道配置中包含了file_extend,但没有安裝logstash-output-file_extend插件。 |
选择以下任意一种方式处理:
|
更多问题原因及解决方法,请参见 Logstash数据写入问题排查方案 。