本文主要讲解到目前为止一些经典的
卷积神经网络
(CNN),这些网络或其衍生网络经常作为其他复杂网络的
backbone
,因此,熟悉这些常见的基本网络还是非常有必要的。本文主要关注的是卷积神经网络的设计哲学,不仅仅局限于某一种网络,还会介绍每一种网络相比之前网络的改进以及为什么要这么做。总之,本文的主要内容就是:
ConvNets Design Philosophy - From AlexNet to DenseNet
声明,本文的部分内容摘自CS231n的课件,我一年多前做的一个PPT和一些其他博主的优秀博客,在文章的最后会给出参考链接。
本篇文章需要一些预备知识:基本的微积分,基本的机器学习知识(比如线性分类器,损失函数,过拟合,欠拟合等),基本的优化方法(如SGD等),反向传播等。
首先给出本文的介绍内容

在介绍基本卷积神经网络之前,我们先来简单回顾一下CNN的基本知识和计算方法,下图是
卷积操作
的示意图:

如果还不是特别清楚,见下面的动图(这个图是当年帮助我入门的图,哈哈哈哈哈哈):
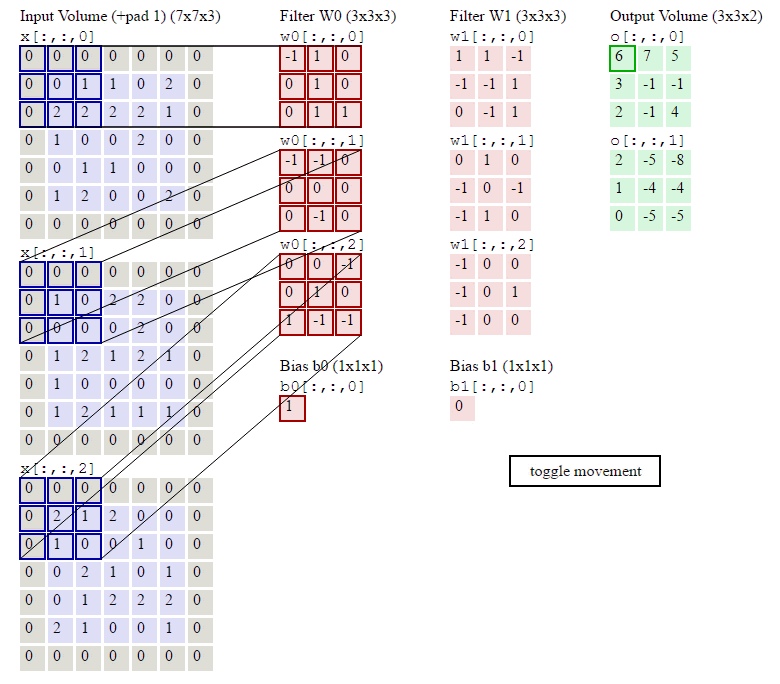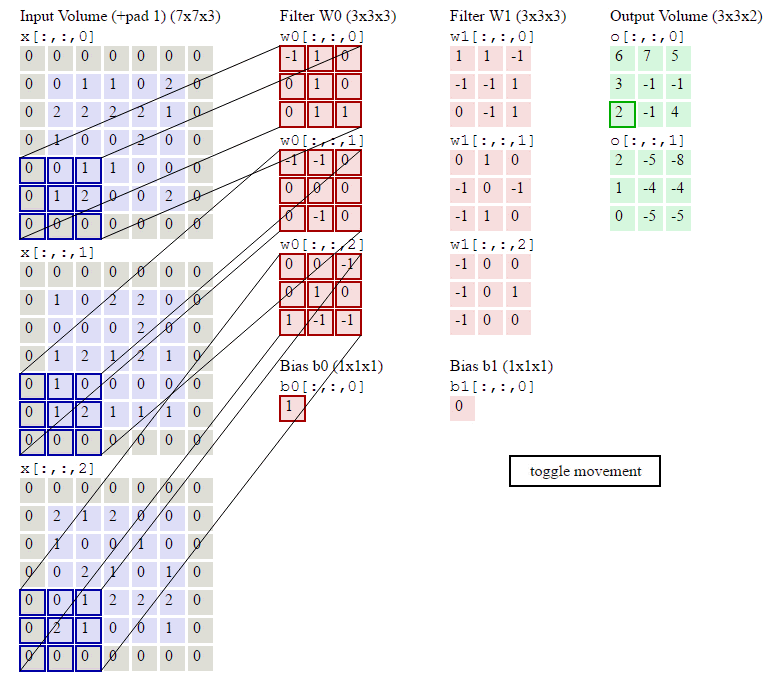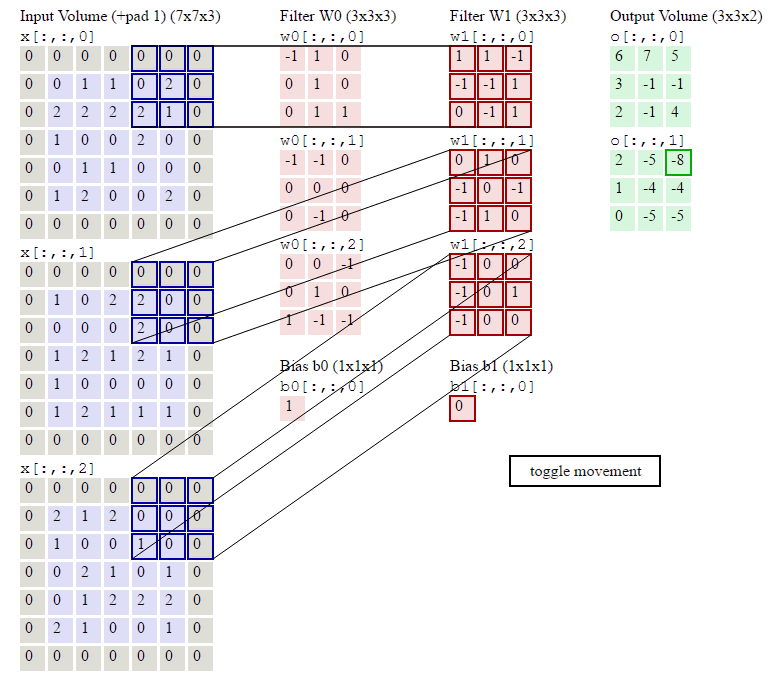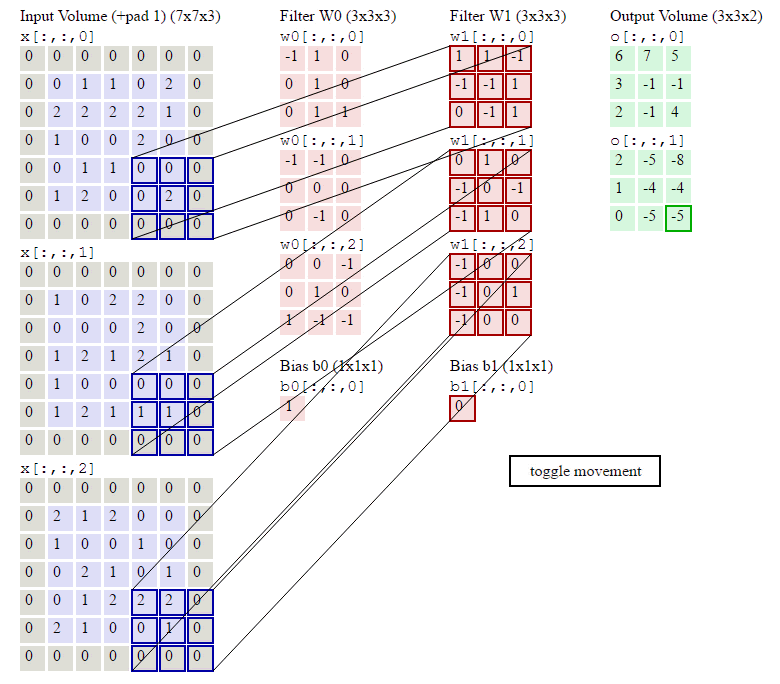
在了解了什么是卷积操作之后,我们还要知道与卷积操作有关的一些
计算
,如下:已知输入数据为
2
8
∗
2
8
∗
5
,计算过程如下:

那么对于每个神经元(例子中为5个),其参数量为多少呢?

好了,在了解了基本卷积过程和其运算之后,下面我们开始具体介绍一些基本的卷积神经网络。
AlexNet(2012)的主要贡献就是在2012年的ImageNet比赛中一举以碾压优势夺冠,开启了用卷积神经网络做图像处理的先河。
AlexNet的
网络结构
如下:

下面还是来关注一下有关AlexNet的卷积操作计算问题(按照上面给出的计算方法是可以算出来的)
layer1:
卷积层

layer2:
最大池化层
(注意:池化层是没有参数的,这一层的参数量为0!)

下面是AlexNet的详细结构图和参数,以及AlexNet当时的一些创新点

ZF-Net(2013),额。。。。这个实在没啥好讲的,其只是对AlexNet做了一点小小的改进。比如将AlexNet的卷积核改小,增加每一层的神经元个数等。

上图中的16.4% -> 11.7%代表的是卷积神经网络在ImageNet数据集上的错误率(人类在这个数据集上的错误率大概为5%)
其实VGG-Net(2014)也算是一个小里程碑,VGG-Net现在也很常见,其对比与Alex-Net的主要改进为:
更小的卷积核,更深的网络
,VGG-Net的网络架构如下:

那么现在有个问题,VGG-Net的两个改进,为什么会能提高网络的性能呢?
使用更小的卷积核是当前在保证网络精度的情况下,减少参数的趋势之一,在VGG16中,使用了
5
∗
5
卷积核。使用更小的卷积核
堆叠
来代替一个大的卷积核,这样做的主要目的是:
-
在保证相同感受野的情况下
-
提升网络的深度
-
提升网络的非线性表达能力(层数多)
-
降低网络模型的参数量
以下简单地说明一下小卷积(
x
,下面主要介绍以下四部分:

在GoogLeNet(2014)之前,网络的设计思路是一直在stack(堆叠)层数,当时的假设是网络越deeper,网络的performance越好。到了2014年,GoogLeNet横空出世,GoogLeNet改变了这个假设:除了增加
深度
,还增加了网络的
宽度
。GoogLeNet的结构如下:

下面我们一步步来推倒出
Inception module
的设计,先来看初始版本的
Naive Inception module
。Naive Inception module就是对同一个输入,用不同大小的卷积核去卷积,然后分别把它们的结果给concatenate(注意这里要求不同卷积操作输出的feature map的大小要相同,不然没法特征拼接呀)起来。但这样有个问题:计算量太大了!

注:上图
p
a
d
d
i
n
g
=
2
(为保证不同卷积操作输出的特征图大小一样,以便于后面的特征拼接)
Naive Inception module的计算量的计算过程如下,可见Naive Inception module的计算量是相当大的(这还只是一层)。

那么我们应该如何减少计算量呢?用的是什么理念和思想呢?
这就不得不提到从2014年一直延续至今的神经网络设计思想:
bottleneck
。使用
bottleneck
(即
所以到这里,Naive Inception module就升级为了
Inception module
。

此时这一个Inception module的计算量为358M ops,相比之前的854M ops,使用“bottleneck”的Inception module的计算量降低了一半多!

到这里,Inception module的结构就介绍完了,而GoogLeNet的架构就是多个Inception module一层一层地stack(
堆叠
)出来的,下面是GoogLeNet的整体架构的介绍。

注:上图中可以看到有三个分类输出头,为什么要用三个classifier呢?结合GoogLeNet的论文,我个人认为有以下几点原因:
-
一般认为深度越深,越有可能产生梯度消失的问题。这里深度不同的三个classifier可以有效缓解梯度消失问题,即浅层的classifier也可以回传误差,缓解梯度消失问题。
-
CNN深度越深的层,提取的特征语义信息越丰富,深度越浅的层提取的特征更基础,包含更多的位置信息,所以并不是深度越深的层提取的特征一定好于较浅层提取的特征。这里在不同深度的层上面都加了一个output layer,可以做一个模型的ensemble,这可能会提升模型的效果。
Inception-V2主要有两点改进:
-
Add Batch Normalization based on Inception-V1.
-
Replace 5x5 and 7x7 conovolutional kernels with 3x3.
其结构如下:
-
Inception-V4 introduces
skip connections
(ResNet) compared with previous Inception series.
即Inception-V4大概就相当于之前的
Inception + ResNet
,因为后面马上就要介绍ResNet,所以这里就不再详细介绍Inception-V4了,只给出其结构图,如下:

-
Very deep networks using residual connections
ResNet(2016)之后,CNN真正到了层数能超过100层(常用ResNet 50,101,152)的时代(甚至训了一个1202层的ResNet,,,吓人)。训练很深的神经网络有一个问题,深度太深,梯度回传困难,很容易发生梯度消失或者爆炸的问题,就是这个原因一直阻碍人们stack更深的网络(因为训不了),很深的模型在模型优化的时候会非常难。
那么如何解决deeper model训练优化困难的问题呢?
solution:
引入残差,使模型训练更easy => 更深的模型性能表现更好这个愿望终于实现了!
Residual Block
的结构如下:

如上所示,ResNet实际上并没有直接学
F
(
x
)
=
H
(
x
)
−
x
。如果了解BP算法(反向传播算法)的话,可能比较好理解反向传播的本质就是链式求导,而ResNet学习的是残差,这样的话在求偏导时就不会出现导数为0的情况(学了一个残差,所以要对残差求偏导)。所以使用ResNet,我们可以训练更深的网络。
ResNet的结构如下:

当然,想优化还可以继续优化……

下面是以上所讲网络模型的性能分析图:

终于到最后一个了,为啥CSDN不能发表情包!难以表达我现在的心情(手动笑哭 * 50)
现在我们有三种方式来处理不同卷积层之间的特征图:
-
Standard Connectivity
-
Residual/Skip Connectivity
-
Densenet: Dense Connectivity
这三种方式的图示如下:
 Standard Connectivity
Standard Connectivity
 Residual/Skip Connectivity
Residual/Skip Connectivity
 Densenet: Dense Connectivity
Densenet: Dense Connectivity
DenseNet的思想是某一层的输入是其前面每一层的输出,即将不同层得到的特征图进行融合作为某一层的输入,这样CNN的每一层就可以得到前面不同层提取的特征(浅层位置等基础信息,深层语义信息),这样网络的表达能力会更好。图示如下:

大家看到这里可能会想,如果每一层的特征图都这样堆叠下去,那么特征图的层数不就无限增长了吗,这样特征的维度就会爆炸!
solution:
用之前提到的
1
∗
1
卷积啊!bottleneck降维

下图是
Dense Blocks
的结构图,在每个Dense Blocks内部,每层的feature map的大小是一致的(方便特征融合),不同Dense Blocks之间有Pooling层用于减小feature map的大小。

至此,DenseNet也算介绍完了,上面就是目前较为常见的基础CNN网络的介绍,重点关注每种网络的设计理念和思想。
欢迎大家有问题积极讨论,谢谢。
文章目录概要介绍基本卷积神经网络(CNN)AlexNetZF-NetVGG-NetInception系列Inception-V1:GoogLeNetInception-V2:An Improved Version of Inception-V1Inception-V3:Factorizing NxN into 1xN and Nx1Inception-V4:Inception with skip...
ResNet
由Kaiming He(何凯明)等发明(论文下载:Deep Residual Learning for Image Recognition),获得了2015年ILSVRC挑战赛的冠军,一度将TOP-5错误率降至3.6%。参加2015年挑战赛区的
ResNet
网络
深度达到
152
层,比起以前的
卷积神经网络
,深度越来越深,但
参数
越来越少。
ResNet
使用了一种叫做残差学习(residual learning)的方法,即将输入越过几层直接添加到后面层的输出上,此时模型不再是简单地拟合目标函数h(x),
输出feature map大小:2828 (32-5+1)=28
神经元
数量:28286
可
训练
参数
:(55+1) * 6(每个滤波器55=25个unit
参数
和一个bias
参数
,一共6个滤波器)
连接数:(55+1)62828=12230
您需要设置两个数据集文件以进行
训练
和验证。 格式必须如下所示:
/absolute/path/to/image1.jpg class_index
/absolute/path/to/image2.jpg class_index
class_index必须从0开始。
可以在和找到样本数据集文件。
不要忘了通过--num_classes运行时,标志finetune.py脚本。
亚历克斯网
进入
alexnet
文件夹
cd
alexnet
如果您以前没有下载过砝码,请下载。
./download_we
乳腺肿瘤
计算
机辅助诊断(CAD)系统在医学检测和诊断
中
的应用日益重要。为了区分核磁共振图像(MRI)
中
肿瘤与非肿瘤,利用深度学习和迁移学习方法,设计了一种新型乳腺肿瘤CAD系统:1)对数据集进行不平衡处理和数据增强;2)在MRI数据集上,利用
卷积神经网络
(
CNN
)提取
CNN
特征,并利用相同的支持向量机分类器,
计算
每层
CNN
的特征图的分类F1分数,选取分类性能最高的一层作为微调节点,其后维度较低层为连接新
网络
节点;3)在选取的
网络
接入节点,连接新设计的两层全连接层组成新的
网络
,利用迁移学习,对新
网络
载入权重;4)采用固定微调节点前的
网络
层不可
训练
,其余层可
训练
的方式微调。分别基于深度卷积
网络
(
VGG
16)、
Inception
V3、深度残差
网络
(
ResNet
50)构建的CAD系统,性能均高于主流的CAD系统,其
中
基于
VGG
16和
ResNet
50搭建的系统性能突出,且二次迁移可以提高
VGG
16系统性能。
五、
VGG
、
AlexNet
、
ResNet
网络
(超详细哦)1、
VGG
网络
1.1、
VGG
网络
结构1.2、理解
VGG
16(
19
)卷积
网络
2、
AlexNet
网络
2.1、
AlexNet
网络
结构2.2、理解
AlexNet
网络
2.3、
Alexnet
网络
中
各层的作用3、
ResNet
网络
1、
VGG
网络
1.1、
VGG
网络
结构
下面是
VGG
网络
的结构(
VGG
16和
VGG
19
都在):
•
VGG
16包含...
在
CNN
网络
结构的进化过程
中
,出现过许多优秀的
CNN
网络
,如:LeNet,
AlexNet
,
VGG
-Net,GoogLeNet,
ResNet
,DesNet.
主要方向:
网络
加深,增强卷积模块
1、LeNet:
LeNet诞生于
19
98年,
网络
结构比较完整,包括卷积层、pooling层、全连接层。被认为是
CNN
的鼻祖。
输入32*32*1
卷积层3个:卷积的主要目的是...
深度残差
网络
ResNet
是2015年ILSVRC的冠军,深度达
152
层,是
VGG
的8倍,top-5错误率为3.6%。
ResNet
的出现使上百甚至上千层的神经
网络
的
训练
成为可能,且
训练
的效果也很好,利用
ResNet
强大的表征能力,使得图像分类、
计算
机视觉(如物体检测和面部识别)的性能都得到了极大的提升。
一、残差学习
根据无限逼近定理(Universal Approximation The...
1、
CNN
的架构模型
CNN
是一种前馈
网络
,即信息流从输入到输出都是单向的。正如人工神经
网络
(ANN)是受生物学启发的,
CNN
也是。大脑的视觉皮层由简单细胞和复杂细胞交替组成(Hubel & Wiesel,
19
59,
19
62),这激发了他们对
CNN
架构的设计。
CNN
的架构有多种变体,通常,它们由卷积层和池化层(subsampling)组成,这些层被分组成模块。在前馈
网络
中
,最后会连接一层或多层全连接层。这些模块通常堆叠在一起,形成一个深层模型。
图像直接输入到
CNN
网络
中
,接下来是几个
AlexNet
是经典的
卷积神经网络
模型架构之一,由Alex Krizhevsky等人在2012年提出。相比于之前LeNet模型,
AlexNet
在深度、
参数
量和
计算
量上都有所提升,使其在图像分类等任务上取得了突破性的成果。
AlexNet
模型包含5个卷积层和3个全连接层,其
中
卷积层之间使用了最大池化操作进行下采样,最后的全连接层作为分类器输出模型的预测结果。模型
中
使用ReLU激活函数来增加非线性,使用Dropout来减轻过拟合问题,使用数据增强来扩充
训练
数据集。
除了
AlexNet
之外,还有一些其他经典的
CNN
模型架构,如
VGG
、GoogleLeNet、
ResNet
等,它们都在不同的任务上表现出色。
VGG
模型采用了更深的
网络
结构,GoogleLeNet使用了
Inception
模块来有效地减少
参数
量,
ResNet
则采用了残差连接来解决深度
网络
中
的梯度消失问题。这些模型为深度学习在
计算
机视觉领域的应用奠定了基础。

