


开源大模型LLaMA(羊驼)论文详解——Facebook母公司Meta推出,超越GPT-3

欢迎关注公众号: 『诗品算法』,禁止一切未经本人 @ 琦琦许可的转载。转载必须注明出处。
引言
之前笔者已经跟大家详细解析过OpenAI的GPT1~GPT3、InstructGPT、ChatGPT,Anthropic的Claude。随着算力的不断发展,模型容量也越来越大,但这些模型均未开源,走向了Close AI之路。不过即使开源,个体也很难玩转这些模型,计算资源(显卡)、数据集等都是困难。
在这样的背景下,国内外涌现出了一批 开源模型 ,近期影响较大的有: Meta AI的LLaMa、斯坦福基于LLama的Alpaca、清华大学的GLM和ChatGLM等 。
本文将为大家详细介绍LLaMA(羊驼)的底层原理。
背景
论文:《LLaMA: Open and Efficient Foundation Language Models》
论文链接: https:// arxiv.org/pdf/2302.1397 1.pdf
开源代码: https:// github.com/facebookrese arch/llama
2023年2月25日,Meta宣布推出一款针对研究社区的基于人工智能的大型语言模型,与微软、谷歌等一众受到 ChatGPT刺激的公司一同卷入人工智能竞赛。
Meta的LLaMA是 “大型语言模型 Meta AI” (Large Language Model Meta AI) 的缩写,它可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者。Meta提供了底层源码供用户使用,因此用户可以自行调整模型,并将其适配于不同领域(开源是人类之光)。该模型对算力的要求“低得多”。
LLaMA包含一系列基础语言模型,大小从7B到65B。模型是用数万亿tokens训练的,且完全使用公开数据集(与开源兼容)。 LLaMA-13B在很多数据集上的表现都优于175B的GPT-3,尽管它比GPT-3小10倍 。LLaMA-65B甚至可以与目前最好的模型竞争——Chinchilla-70B和PaLM-540B。
一、介绍
目前业界有一种普遍认知,更多的模型参数,更大的模型容量,将会带来更好的模型性能,这导致模型的规模越来越大。而Hoffmann最近的研究表示,当计算资源恒定时,最佳性能并非通过最大的模型达到,而是通过在更多数据上训练较小模型实现的;他们的工作正是根据训练计算的预算,灵活地调整数据集和模型大小。然而,这个目标忽略了推理预算。首选模型不应该是训练最快的,而应该是推理最快的。尽管训练大模型以达到预期性能水平可能比较便宜,但训练一个更小、训练耗时更长的模型最终会使推理过程更便宜。
二、方法
2.1 预训练数据
这篇文章使用的数据集来源于多个不同领域,尽量重用已被用来训练其他LLM的数据源(限制只使用公开且与开源兼容的数据集)。数据集采样分布如下表所示。
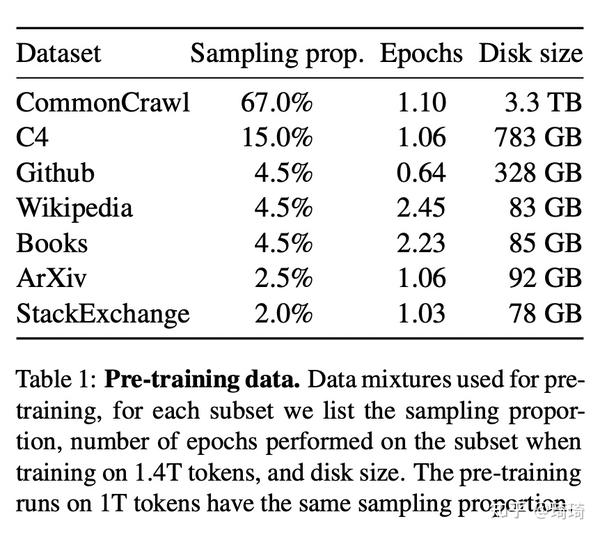
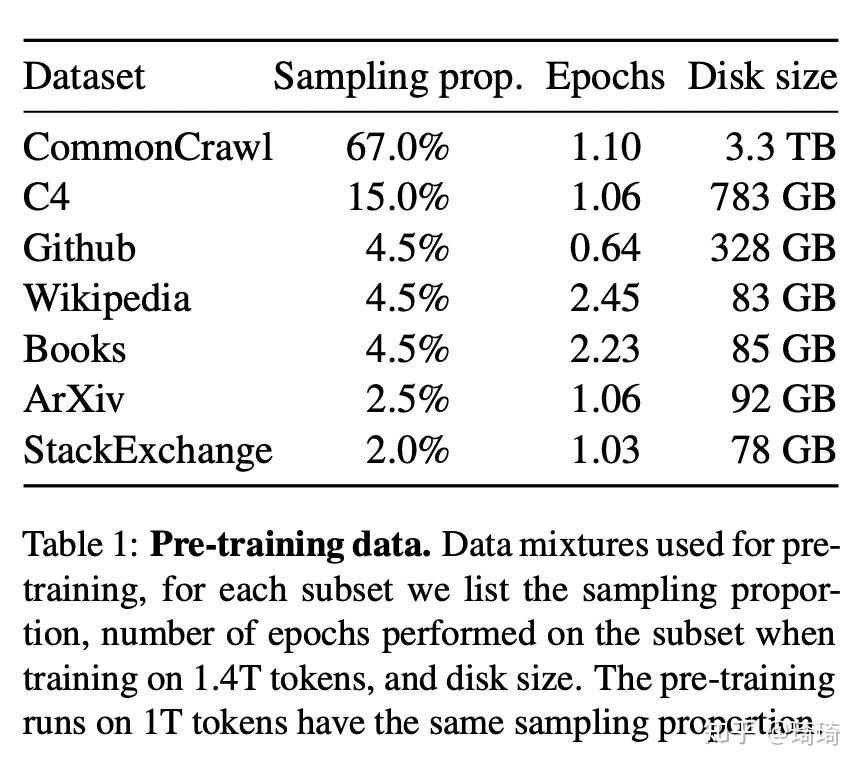
下面简要列出文章对这些数据集进行的一些预处理:
1)English CommonCrawl [67%]:在行级别消除重复数据;删除非英文页面(使用fastText线性分类器执行语言识别任务);过滤低质量内容(使用n-gram语言模型)。
2)C4 [15%]:与上面类似,消除重复数据、语言识别、过滤低质量内容(启发式过滤)。
3)Github [4.5%]:基于行长度或字母数字的比例过滤低质量文件(启发式过滤)、删除样板文件(使用正则表达式)、在文件级别消除重复数据。
4)Wikipedia [4.5%]:删除超链接、注释、样板文件。
5)Gutenberg and Books3 [4.5%]:在书籍层面去重,移除具有90%内容重复的书籍。
6)ArXiv [2.5%]:删除第一节之前的所有内容、删除参考书目、删除.tex文件中的注释。
7)Stack Exchange [2%]:保留28个最大网站的数据,从文本中移除HTML标签,将答案按照分数高低进行排序。
模型在Wikipedia和Books数据集上训练两个epoch,在其他数据集上训练一个epoch。
2.2 结构
也是基于经典的Transformer架构,在此基础上做了一些微小改进。
1、预标准化[GPT3]: 为了提高训练的稳定性,对每个transformer子layer的输入进行normalize,而不是对输出进行normalize。使用的归一化函数是RMSNorm。
2、 SwiGLU激活函数[PaLM] :使用SwiGLU激活函数替代ReLU非线性激活函数,以提高模型性能。
3、 旋转embeddings[GPTNeo] :删除了绝对位置embeddings,在网络的每一层layer都添加了旋转位置embeddings。
本文不同模型的详细超参信息如下:
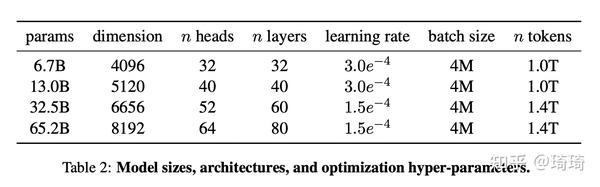
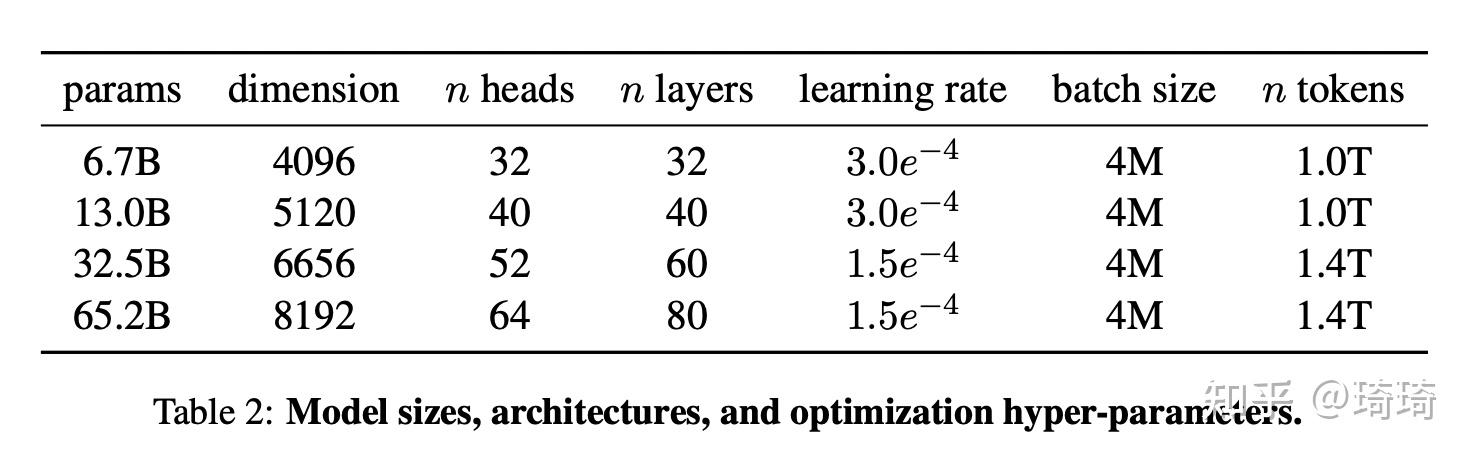
2.3 优化器
1、使用AdamW优化器;超参数: \beta_1=0.9, \beta_2=0.95 。使用0.1的weight decay,梯度裁剪为1.0。
2、余弦学习率,且最终学习率为最大学习率的10%。
3、使用2000个预热step,且会随着模型大小的变化,改变学习率和batch_size。
2.4 优化训练速度
提升模型训练速度:
1、因果多头注意力机制,减少内存使用和运行时间,具体是通过通过不存储注意力权重以及不计算被mask的key/query分数来实现的。具体实现细节可参照论文: Flashattention: Fast and memory-efficient exact attention with io-awareness 。
这里给大家简要介绍一下Flashattention的思想。我们知道,LLM所依赖的底层Transformer架构,其核心的自注意力机制(self-attention)的时间和存储复杂度在序列长度上属于二次型。有人提出近似注意力的方法,来减少attention计算和内存需求。这种方法过于关注Flops(每秒所运行的浮点运算次数),而忽略了IO(内存访问)的开销。 FlashAttention把IO开销也考虑在内,通过减少GPU内存读取和写入,FlashAttention的运行速度相比于标准注意力PyTorch快2~4倍,所需的内存减少了5~20倍。 传统attention在计算时,需要进行多次对高带宽显存HBM(High Bandwidth Memory)的读和写,占用很大的开销。
FlashAttention为了避免从HBM中读取和写入注意力矩阵,做到了以下两点:
1) 在不访问整个输入的情况下计算softmax函数的缩减。具体是将输入分成块,以输入块的方式进行多次传递,以增量方式计算softmax的缩减,这样可以大大加快运行速度;
2) 在反向传播中不存储中间注意力矩阵,而是存储前向传递的softmax归一化因子。通过归一化因子,在反向传播中,重新计算两个中间注意力矩阵,虽然运算次数(Flops)增加,但是对HBM的读写有明显降低,这样可以大大节省所占用的内存。 FlashAttention是在GPT-2模型上进行实验的,对于LLM的优化也有很好的借鉴意义。
2、 减少在反向传播中需要重新计算的激活函数数量。 更准确地说,保存了那些计算成本高昂的节点,比如线性层的输出。这是通过手动实现transformer层的反向函数达到的,而不是依赖PyTorch自带的autograd。
3、使网络GPU之间的激活函数计算以及通信尽可能重叠,以减少计算。
三、实验结果
跟GPT类似,这篇文章考虑了zero-shot和few-shot的情况。
1、zero-shot:提供任务的文本描述和一个测试示例。模型提供开放式的答案,或者对给出的答案进行排序。
2、few-shot:提供任务的一些示例(1~64个例子)和一个测试示例。模型将文本作为输入,给出答案,或者对不同答案进行排序。
作者将LLaMA模型与业界其他比较流行的大模型进行了对比。下面列出几个有代表性的结果。
1、常识推理。在所有数据集上,LLaMA-65B模型都比Chinchilla-70B模型的表现要好;同样在大多数数据集上,LLaMA-13B都比GPT-3-175B的表现好,尽管LLaMA-13B的模型参数量比GPT-3少了10倍。
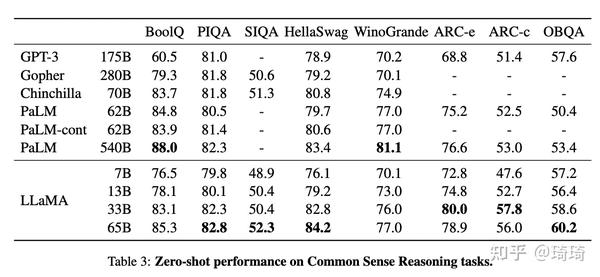
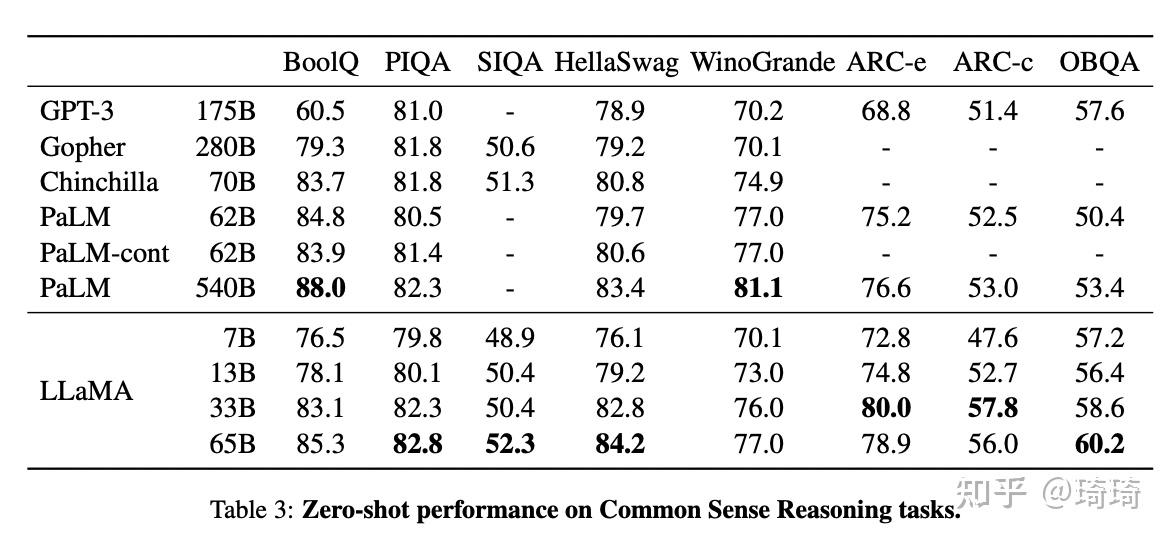
2、闭卷问答。在NaturalQuestions数据集上,LLaMA-13B模型的表现优于GPT-3-175B。
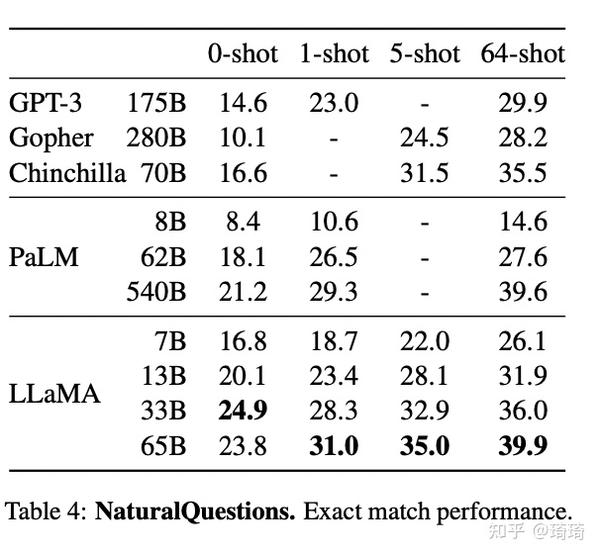
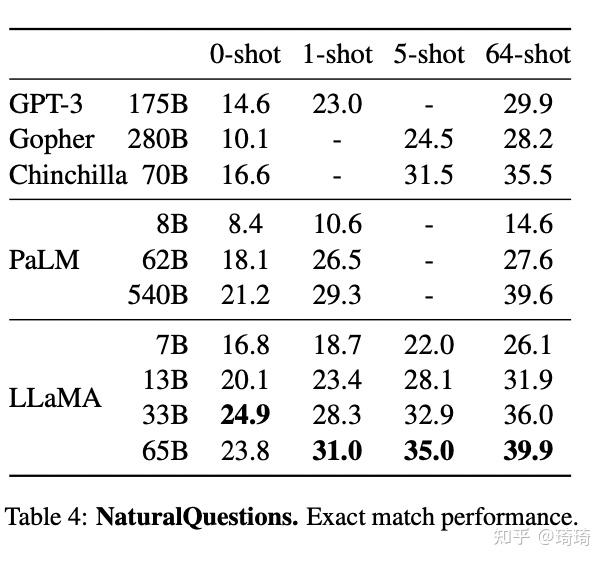
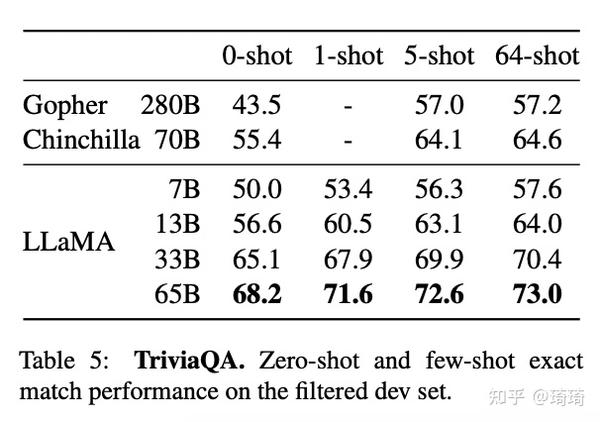
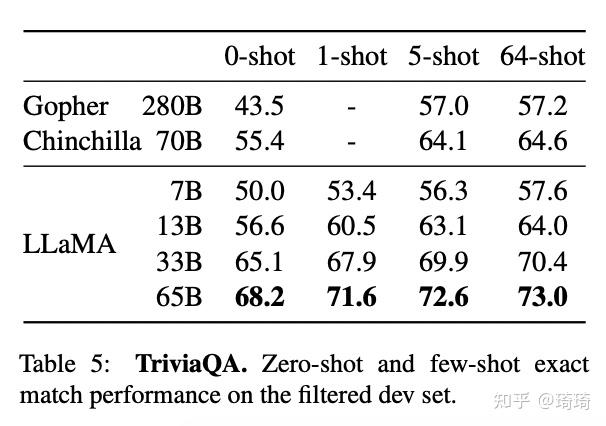
除此以外,
1)在阅读理解、代码生成领域,优于GPT-3或者PaLM模型。
2)在数学推理领域表现欠佳,作者给出的原因是没有在数学数据上进行过finetune。
3)在大规模多任务语言理解领域表现欠佳,不如Chinchilla-70B和PaLM-540B模型,原因是LLaMA在预训练数据集中,仅仅使用了很少一部分书籍和专业论文(177G VS 其他模型的2TB)。
四、指令微调
尽管未进行微调的LLaMA-65B模型已经能在很多领域和一些大模型battle,作者发现,少量微调仍然可以迅速提升模型在MMLU数据集上的表现。作者给出了一个简单的实验结果,如下图。
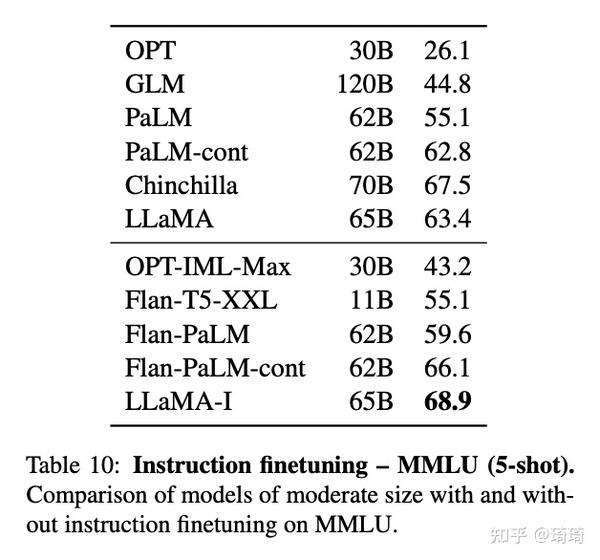

五、偏见、毒性和错误信息
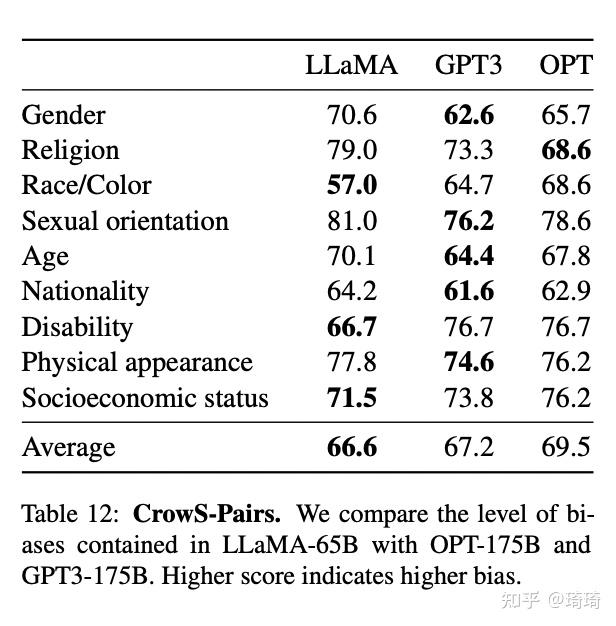
在这部分内容中,作者提到,LLaMA的训练数据集包含了大量源于Web中的内容,因此也有可能生成一些有毒或有攻击性的内容。为了了解LLaMA-65B模型的潜在危害,作者在不同基准上,对模型的有毒文本生成等方面进行了评估。比如,在CrowS-Pairs数据集上,对LLaMA和GPT3、OPT的偏见得分进行比较,在9种不同的偏见评估类别下,LLaMA的偏见得分均值略低于GPT3和OPT模型。
如下图:
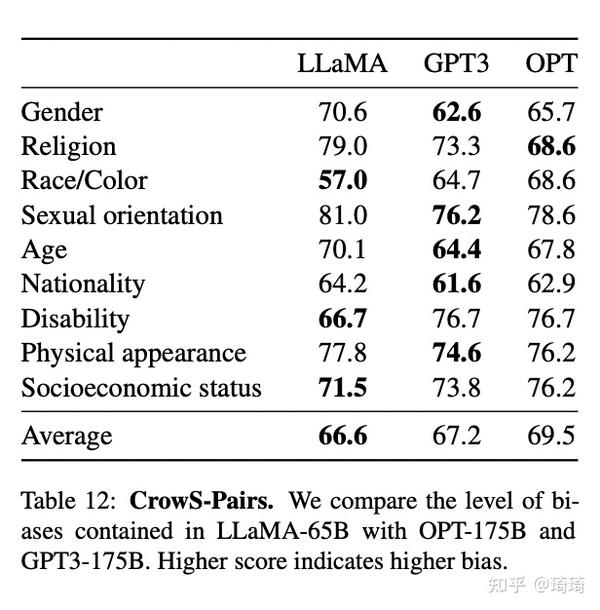
这篇文章的最后,作者还写了一个章节,专门用来探讨LLaMA大模型的二氧化碳排放量情况(由于模型计算消耗了大量的能量),也是比较有趣。
Reference
1、LLaMA: Open and Efficient Foundation Language Models
2、Flashattention: Fast and memory-efficient exact attention with io-awareness
