link之家
链接快照平台
- 输入网页链接,自动生成快照
- 标签化管理网页链接
相关文章推荐

|
强健的南瓜 · MySQL之TPC压缩-CSDN博客· 8 月前 · |
|
|
痴情的弓箭 · Troubleshooting 502 ...· 1 年前 · |
|
|
慷慨大方的薯片 · java8 stream流操作 - 知乎· 1 年前 · |
|
|
微醺的红茶 · docker 网络问题 ...· 1 年前 · |

JavaREST 客户端有两种模式:
下面介绍下 SpringBoot 如何通过 elasticsearch-rest-high-level-client 工具操作 ElasticSearch。当然也可以通过 spring-data-elasticsearch 来操作 ElasticSearch,而本文仅是 elasticsearch-rest-high-level-client 的案例介绍,所以本文中我并未使用 spring-data-elasticsearch,后期我会补上。
注意事项:客户端 (Client) Jar 包的版本尽量不要大于 Elasticsearch 本体的版本,否则可能出现客户端中使用的某些 API 在 Elasticsearch 中不支持。
这里需要说一下,能使用 RestHighLevelClient 尽量使用它,为什么不推荐使用 Spring 家族封装的 spring-data-elasticsearch。主要原因是灵活性和更新速度,Spring 将 ElasticSearch 过度封装,让开发者很难跟 ES 的 DSL 查询语句进行关联。再者就是更新速度,ES 的更新速度是非常快,但是 spring-data-elasticsearch 更新速度比较缓慢。并且 spring-data-elasticsearch 在 Elasticsearch6.x 和 7.x 版本上的 Java API 差距很大,如果升级版本需要花点时间来了解。
TIPS:spring-data-elasticsearch 的底层其实也是否则了 elasticsearch-rest-high-level-client 的 api。
2、引入依赖
特别注意:引入的依赖最好与 SpringBoot 中的版本一样,免得出现版本冲突。
<!--引入es-high-level-client的坐标-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
完整的 Maven 依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.thr.elasticsearch</groupId>
<artifactId>elasticsearch-rest-high-level-client-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>elasticsearch-rest-high-level-client-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.3.7.RELEASE</spring-boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--引入es-high-level-client的坐标-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.72</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.3.7.RELEASE</version>
<configuration>
<mainClass>com.thr.elasticsearch.ESRestHighLevelClientApplication</mainClass>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
3、ES 的配置
(1)、创建索引
PUT /goods
"mappings": {
"properties": {
"brandName": {
"type": "keyword"
"categoryName": {
"type": "keyword"
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
"id": {
"type": "keyword"
"price": {
"type": "double"
"saleNum": {
"type": "integer"
"status": {
"type": "integer"
"stock": {
"type": "integer"
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
(2)、application.yml 配置文件
elasticsearch:
host: 116.205.230.143
port: 9200
spring:
# 应用名称
application:
name: elasticsearch-spring-data
datasource:
username: root
password: 123456
url: jdbc:mysql://116.205.230.143:3306/es?useSSL=false&serverTimezone=UTC&characterEncoding=utf8&allowMultiQueries=true
driver-class-name: com.mysql.cj.jdbc.Driver
elasticsearch:
rest:
# 定位ES的位置
uris: http://116.205.230.143:9200
mybatis:
type-aliases-package: com.thr.elastisearch.domain
mapper-locations: classpath:mapper/*.xml
(3)、java 连接配置类
写一个 Java 配置类读取 application 中的配置信息:
* ES的配置类
* ElasticSearchConfig
* @author tanghaorong
@Data
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {
private String host;
private Integer port;
* 如果@Bean没有指定bean的名称,那么这个bean的名称就是方法名
@Bean
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(
RestClient.builder(
new HttpHost(host, port, "http")
(4)、mybatis 配置
* Mapper接口
* @author tanghaorong
@Repository
@Mapper
public interface GoodsMapper {
* 查询所有
List<Goods> findAll();
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.elasticsearch.dao.GoodsMapper">
<select id="findAll" resultType="com.thr.elasticsearch.domain.Goods">
select `id`,
`title`,
`price`,
`stock`,
`saleNum`,
`createTime`,
`categoryName`,
`brandName`,
`status`
from goods
</select>
</mapper>
(5)、实体对象
@Data
@Accessors(chain = true) // 链式赋值(连续set方法)
@AllArgsConstructor // 全参构造
@NoArgsConstructor // 无参构造
public class Goods {
* 商品编号
private Long id;
* 商品标题
private String title;
* 商品价格
private BigDecimal price;
* 商品库存
private Integer stock;
* 商品销售数量
private Integer saleNum;
* 商品分类
private String categoryName;
* 商品品牌
private String brandName;
* 上下架状态
private Integer status;
* 商品创建时间
@JSONField(format = "yyyy-MM-dd HH:mm:ss")
private Date createTime;
(6)、测试类
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESRestHighLevelClientApplicationTests {
@Test
public void test1() throws IOException {
需要注意的是,测试启动类要和项目的启动类位于同一个包中,否则启动可能会报错。
(7)、项目整体结构
4、索引操作
* 创建索引库和映射表结构
* 注意:索引一般不会怎么创建
@Test
public void indexCreate() throws Exception {
IndicesClient indicesClient = restHighLevelClient.indices();
// 创建索引
CreateIndexRequest indexRequest = new CreateIndexRequest("goods111");
// 创建表 结构
String mapping = "{\n" +
" \"properties\": {\n" +
" \"brandName\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"categoryName\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"createTime\": {\n" +
" \"type\": \"date\",\n" +
" \"format\": \"yyyy-MM-dd HH:mm:ss\"\n" +
" },\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"double\"\n" +
" },\n" +
" \"saleNum\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"status\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"stock\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"title\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"search_analyzer\": \"ik_smart\"\n" +
" }\n" +
" }\n" +
" }";
// 把映射信息添加到request请求里面
// 第一个参数:表示数据源
// 第二个参数:表示请求的数据类型
indexRequest.mapping(mapping, XContentType.JSON);
// 请求服务器
CreateIndexResponse response = indicesClient.create(indexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
* 获取表结构
* GET goods/_mapping
@Test
public void getMapping() throws Exception {
IndicesClient indicesClient = restHighLevelClient.indices();
// 创建get请求
GetIndexRequest request = new GetIndexRequest("goods");
// 发送get请求
GetIndexResponse response = indicesClient.get(request, RequestOptions.DEFAULT);
// 获取表结构
Map<String, MappingMetaData> mappings = response.getMappings();
for (String key : mappings.keySet()) {
System.out.println("key--" + mappings.get(key).getSourceAsMap());
* 删除索引库
@Test
public void indexDelete() throws Exception {
IndicesClient indicesClient = restHighLevelClient.indices();
// 创建delete请求方式
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("goods");
// 发送delete请求
AcknowledgedResponse response = indicesClient.delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
* 判断索引库是否存在
@Test
public void indexExists() throws Exception {
IndicesClient indicesClient = restHighLevelClient.indices();
// 创建get请求
GetIndexRequest request = new GetIndexRequest("goods");
// 判断索引库是否存在
boolean result = indicesClient.exists(request, RequestOptions.DEFAULT);
System.out.println(result);
5、文档操作
* 增加文档信息
@Test
public void addDocument() throws IOException {
// 创建商品信息
Goods goods = new Goods();
goods.setId(1L);
goods.setTitle("Apple iPhone 13 Pro (A2639) 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机");
goods.setPrice(new BigDecimal("8799.00"));
goods.setStock(1000);
goods.setSaleNum(599);
goods.setCategoryName("手机");
goods.setBrandName("Apple");
goods.setStatus(0);
goods.setCreateTime(new Date());
// 将对象转为json
String data = JSON.toJSONString(goods);
// 创建索引请求对象 (new IndexRequest()中的第二个参数, 必须为"_doc")
IndexRequest indexRequest = new IndexRequest("goods", "_doc").id(goods.getId() + "").source(data, XContentType.JSON);
// 执行增加文档
IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
log.info("创建状态:{}", response.status());
* 获取文档信息
@Test
public void getDocument() throws IOException {
// 创建获取请求对象
GetRequest getRequest = new GetRequest("goods", "1");
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
* 更新文档信息
@Test
public void updateDocument() throws IOException {
// 设置商品更新信息
Goods goods = new Goods();
goods.setTitle("Apple iPhone 13 Pro Max (A2644) 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机");
goods.setPrice(new BigDecimal("9999"));
// 将对象转为json
String data = JSON.toJSONString(goods);
// 创建索引请求对象
UpdateRequest updateRequest = new UpdateRequest("goods", "1");
// 设置更新文档内容
updateRequest.doc(data, XContentType.JSON);
// 执行更新文档
UpdateResponse response = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("创建状态:{}", response.status());
* 删除文档信息
@Test
public void deleteDocument() throws IOException {
// 创建删除请求对象
DeleteRequest deleteRequest = new DeleteRequest("goods", "1");
// 执行删除文档
DeleteResponse response = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("删除状态:{}", response.status());
6、导入测试数据
下载测试数据
下载链接:files.cnblogs.com/files/tangh…
下载后导入数据库中,大概有 900 多条。
导入测试数据至 ES 中:
* 批量导入测试数据
@Test
public void importData() throws IOException {
//1.查询所有数据,mysql
List<Goods> goodsList = goodsMapper.findAll();
//2.bulk导入
BulkRequest bulkRequest = new BulkRequest();
//2.1 循环goodsList,创建IndexRequest添加数据
for (Goods goods : goodsList) {
//将goods对象转换为json字符串
String data = JSON.toJSONString(goods);//map --> {}
IndexRequest indexRequest = new IndexRequest("goods");
indexRequest.id(goods.getId() + "").source(data, XContentType.JSON);
bulkRequest.add(indexRequest);
BulkResponse response = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(response.status());
导入成功。
7、DSL 高级查询操作
精确查询 (term)
term 查询:不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配,也就是精确查找,比如数字,日期,布尔值或 not_analyzed 的字符串 (未经分析的文本数据类型)
terms 查询:terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去 做匹配:
* 精确查询(termQuery)
@Test
public void termQuery() {
try {
// 构建查询条件(注意:termQuery 支持多种格式查询,如 boolean、int、double、string 等,这里使用的是 string 的查询)
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("title", "华为"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info("=======" + userInfo.toString());
} catch (IOException e) {
log.error("", e);
* terms:多个查询内容在一个字段中进行查询
@Test
public void termsQuery() {
try {
// 构建查询条件(注意:termsQuery 支持多种格式查询,如 boolean、int、double、string 等,这里使用的是 string 的查询)
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termsQuery("title", "华为", "OPPO", "TCL"));
// 展示100条,默认只展示10条记录
searchSourceBuilder.size(100);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
全文查询 (match)
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集。
term 和 match 的区别是:match 是经过 analyer 的,也就是说,文档首先被分析器给处理了。根据不同的分析器,分析的结果也稍显不同,然后再根据分词结果进行匹配。term 则不经过分词,它是直接去倒排索引中查找了精确的值了。
match 查询语法汇总:
match_all:查询全部。
match:返回所有匹配的分词。
match_phrase:短语查询,在 match 的基础上进一步查询词组,可以指定 slop 分词间隔。
match_phrase_prefix:前缀查询,根据短语中最后一个词组做前缀匹配,可以应用于搜索提示,但注意和 max_expanions 搭配。其实默认是 50.......
multi_match:多字段查询,使用相当的灵活,可以完成 match_phrase 和 match_phrase_prefix 的工作。
* 匹配查询符合条件的所有数据,并设置分页
@Test
public void matchAllQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 设置分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 设置排序
searchSourceBuilder.sort("price", SortOrder.ASC);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
* 匹配查询数据
@Test
public void matchQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("title", "华为"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
* 词语匹配查询
@Test
public void matchPhraseQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchPhraseQuery("title", "三星"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
* 内容在多字段中进行查询
@Test
public void matchMultiQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("手机", "title", "categoryName"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
通配符查询 (wildcard)
wildcard 查询:会对查询条件进行分词。还可以使用通配符 ?(任意单个字符) 和 * (0 个或多个字符)
* 查询所有以 “三” 结尾的商品信息
* *:表示多个字符(0个或多个字符)
* ?:表示单个字符
@Test
public void wildcardQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.wildcardQuery("title", "*三"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
模糊查询 (fuzzy)
* 模糊查询所有以 “三” 结尾的商品信息
@Test
public void fuzzyQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.fuzzyQuery("title", "三").fuzziness(Fuzziness.AUTO));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
排序查询 (sort)
注意:需要分词的字段不可以直接排序,比如:text 类型,如果想要对这类字段进行排序,需要特别设置:对字段索引两次,一次索引分词(用于搜索)一次索引不分词(用于排序),es 默认生成的 text 类型字段就是通过这样的方法实现可排序的。
* 排序查询(sort) 代码同matchAllQuery
* 匹配查询符合条件的所有数据,并设置分页
@Test
public void matchAllQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 设置分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 设置排序
searchSourceBuilder.sort("price", SortOrder.ASC);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
分页查询 (page)
Elasticsearchde 的分页查询和 SQL 使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch 接受 from 和 size 参数:
size: 结果数,默认 10
from: 跳过开始的结果数,即从哪一行开始获取数据,默认 0
这种方式分页查询如果需要深度分页,那么这种方式性能不太好。
* 分页查询(page) 代码同matchAllQuery
* 匹配查询符合条件的所有数据,并设置分页
@Test
public void matchAllQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 设置分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 设置排序
searchSourceBuilder.sort("price", SortOrder.ASC);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
滚动查询 (scroll)
滚动查询可以优化 ES 的深度分页,但是需要维护 scrollId
* 根据查询条件滚动查询
* 可以用来解决深度分页查询问题
@Test
public void scrollQuery() {
// 假设用户想获取第70页数据,其中每页10条
int pageNo = 70;
int pageSize = 10;
// 定义请求对象
SearchRequest searchRequest = new SearchRequest("goods");
// 构建查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
searchRequest.source(builder.query(QueryBuilders.matchAllQuery()).size(pageSize));
String scrollId = null;
// 3、发送请求到ES
SearchResponse scrollResponse = null;
// 设置游标id存活时间
Scroll scroll = new Scroll(TimeValue.timeValueMinutes(2));
// 记录所有游标id
List<String> scrollIds = new ArrayList<>();
for (int i = 0; i < pageNo; i++) {
try {
// 首次检索
if (i == 0) {
//记录游标id
searchRequest.scroll(scroll);
// 首次查询需要指定索引名称和查询条件
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 下一次搜索要用到该游标id
scrollId = response.getScrollId();
// 记录所有游标id
// 非首次检索
else {
// 不需要在使用其他条件,也不需要指定索引名称,只需要使用执行游标id存活时间和上次游标id即可,毕竟信息都在上次游标id里面呢
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(scroll);
scrollResponse = restHighLevelClient.scroll(searchScrollRequest, RequestOptions.DEFAULT);
// 下一次搜索要用到该游标id
scrollId = scrollResponse.getScrollId();
// 记录所有游标id
scrollIds.add(scrollId);
} catch (Exception e) {
e.printStackTrace();
//清除游标id
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.scrollIds(scrollIds);
try {
restHighLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
System.out.println("清除滚动查询游标id失败");
e.printStackTrace();
// 4、处理响应结果
System.out.println("滚动查询返回数据:");
assert scrollResponse != null;
SearchHits hits = scrollResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(goods.toString());
范围查询 (range)
* 查询价格大于等于10000的商品信息
@Test
public void rangeQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.rangeQuery("price").gte(10000));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
log.info(hits.getTotalHits().value + "");
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
* 查询距离现在 10 年间的商品信息
* [年(y)、月(M)、星期(w)、天(d)、小时(h)、分钟(m)、秒(s)]
* 例如:
* now-1h 查询一小时内范围
* now-1d 查询一天内时间范围
* now-1y 查询最近一年内的时间范围
@Test
public void dateRangeQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// includeLower(是否包含下边界)、includeUpper(是否包含上边界)
searchSourceBuilder.query(QueryBuilders.rangeQuery("createTime")
.gte("now-10y").includeLower(true).includeUpper(true));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
} catch (IOException e) {
log.error("", e);
布尔查询 (bool)
bool 查询可以用来合并多个条件查询结果的布尔逻辑,它包含一下操作符:
must:多个查询条件必须完全匹配,相当于关系型数据库中的 and。
should:至少有一个查询条件匹配,相当于关系型数据库中的 or。
must_not: 多个查询条件的相反匹配,相当于关系型数据库中的 not。
filter:过滤满足条件的数据。
range:条件筛选范围。
gt:大于,相当于关系型数据库中的 >。
gte:大于等于,相当于关系型数据库中的 >=。
lt:小于,相当于关系型数据库中的 <。
lte:小于等于,相当于关系型数据库中的 <=。
// 创建 Bool 查询构建器
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 构建查询条件
boolQueryBuilder.must(QueryBuilders.matchQuery("title", "三星"))
.filter().add(QueryBuilders.rangeQuery("createTime").format("yyyy").gte("2018").lte("2022"));
// 构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(100);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(goods.toString());
} catch (IOException e) {
log.error("", e);
queryString 查询
会对查询条件进行分词, 然后将分词后的查询条件和词条进行等值匹配,默认取并集(OR),可以指定单个字段也可多个查询字段
* queryStringQuery查询
* 案例:查询出必须包含 华为手机 词语的商品信息
@Test
public void queryStringQuery() {
try {
// 创建 queryString 查询构建器
QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery("华为手机").defaultOperator(Operator.AND);
// 构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryStringQueryBuilder);
searchSourceBuilder.size(100);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(goods.toString());
} catch (IOException e) {
log.error("", e);
查询结果过滤
我们在查询数据的时候,返回的结果中,所有字段都给我们返回了,但是有时候我们并不需要那么多,所以可以对结果进行过滤处理。
* 过滤source获取部分字段内容
* 案例:只获取 title、categoryName和price的数据
@Test
public void sourceFilter() {
try {
//查询条件(词条查询:对应ES query里的match)
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("title", "金立"))
.must(QueryBuilders.matchQuery("categoryName", "手机"))
.filter(QueryBuilders.rangeQuery("price").gt(1000).lt(2000));
// 构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQueryBuilder);
// 如果查询的属性很少,那就使用includes,而excludes设置为空数组
// 如果排序的属性很少,那就使用excludes,而includes设置为空数组
String[] includes = {"title", "categoryName", "price"};
String[] excludes = {};
searchSourceBuilder.fetchSource(includes, excludes);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(goods.toString());
} catch (IOException e) {
log.error("", e);
* 高亮查询
* 案例:把标题中为 三星手机 的词语高亮显示
@Test
public void highlightBuilder() {
try {
//查询条件(词条查询:对应ES query里的match)
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "三星手机");
//设置高亮三要素 field: 你的高亮字段 // preTags :前缀 // postTags:后缀
HighlightBuilder highlightBuilder = new HighlightBuilder().field("title").preTags("<font color='red'>").postTags("</font>");
// 构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchQueryBuilder);
searchSourceBuilder.highlighter(highlightBuilder);
searchSourceBuilder.size(100);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 获取高亮的数据
HighlightField highlightField = hit.getHighlightFields().get("title");
System.out.println("高亮名称:" + highlightField.getFragments()[0].string());
// 替换掉原来的数据
Text[] fragments = highlightField.getFragments();
if (fragments != null && fragments.length > 0) {
StringBuilder title = new StringBuilder();
for (Text fragment : fragments) {
//System.out.println(fragment);
title.append(fragment);
goods.setTitle(title.toString());
// 输出查询信息
log.info(goods.toString());
} catch (IOException e) {
log.error("", e);
我们平时在使用 Elasticsearch 时,更多会用到聚合操作,它类似 SQL 中的 group by 操作。ES 的聚合查询一定是先查出结果,然后对结果使用聚合函数做处理,常用的操作有:avg:求平均、max:最大值、min:最小值、sum:求和等。
在 ES 中聚合分为指标聚合和分桶聚合:
Metric 指标聚合:指标聚合对一个数据集求最大、最小、和、平均值等
Bucket 分桶聚合:除了有上面的聚合函数外,还可以对查询出的数据进行分组 group by,再在组上进行游标聚合。
Metric 指标聚合分析
* 聚合查询
* Metric 指标聚合分析
* 案例:分别获取最贵的商品和获取最便宜的商品
@Test
public void metricQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 获取最贵的商品
AggregationBuilder maxPrice = AggregationBuilders.max("maxPrice").field("price");
searchSourceBuilder.aggregation(maxPrice);
// 获取最便宜的商品
AggregationBuilder minPrice = AggregationBuilders.min("minPrice").field("price");
searchSourceBuilder.aggregation(minPrice);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedMax max = aggregations.get("maxPrice");
log.info("最贵的价格:" + max.getValue());
ParsedMin min = aggregations.get("minPrice");
log.info("最便宜的价格:" + min.getValue());
} catch (IOException e) {
log.error("", e);
* 聚合查询
* Bucket 分桶聚合分析
* 案例:根据品牌进行聚合查询
@Test
public void bucketQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 根据商品分类进行分组查询
TermsAggregationBuilder aggBrandName = AggregationBuilders.terms("brandNameName").field("brandName");
searchSourceBuilder.aggregation(aggBrandName);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedStringTerms aggBrandName1 = aggregations.get("brandNameName");
for (Terms.Bucket bucket : aggBrandName1.getBuckets()) {
System.out.println(bucket.getKeyAsString() + "====" + bucket.getDocCount());
} catch (IOException e) {
log.error("", e);
Bucket 分桶聚合分析
* 聚合查询
* Bucket 分桶聚合分析
* 案例:根据品牌进行聚合查询
@Test
public void bucketQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 根据商品分类进行分组查询
TermsAggregationBuilder aggBrandName = AggregationBuilders.terms("brandNameName").field("brandName");
searchSourceBuilder.aggregation(aggBrandName);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedStringTerms aggBrandName1 = aggregations.get("brandNameName");
for (Terms.Bucket bucket : aggBrandName1.getBuckets()) {
System.out.println(bucket.getKeyAsString() + "====" + bucket.getDocCount());
} catch (IOException e) {
log.error("", e);
* 子聚合聚合查询
* Bucket 分桶聚合分析
* 案例:根据商品分类进行分组查询,并且获取分类商品中的平均价格
@Test
public void subBucketQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 根据商品分类进行分组查询,并且获取分类商品中的平均价格
TermsAggregationBuilder subAggregation = AggregationBuilders.terms("brandNameName").field("brandName")
.subAggregation(AggregationBuilders.avg("avgPrice").field("price"));
searchSourceBuilder.aggregation(subAggregation);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedStringTerms aggBrandName1 = aggregations.get("brandNameName");
for (Terms.Bucket bucket : aggBrandName1.getBuckets()) {
// 获取聚合后的品牌的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg avgPrice = bucket.getAggregations().get("avgPrice");
System.out.println(bucket.getKeyAsString() + "====" + avgPrice.getValueAsString());
} catch (IOException e) {
log.error("", e);
综合聚合查询
* 综合聚合查询
* 根据商品分类聚合,获取每个商品类的平均价格,并且在商品分类聚合之上子聚合每个品牌的平均价格
@Test
public void subSubAgg() throws IOException {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 注意这里聚合写的位置不要写错,很容易搞混,错一个括号就不对了
TermsAggregationBuilder subAggregation = AggregationBuilders.terms("categoryNameAgg").field("categoryName")
.subAggregation(AggregationBuilders.avg("categoryNameAvgPrice").field("price"))
.subAggregation(AggregationBuilders.terms("brandNameAgg").field("brandName")
.subAggregation(AggregationBuilders.avg("brandNameAvgPrice").field("price")));
searchSourceBuilder.aggregation(subAggregation);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
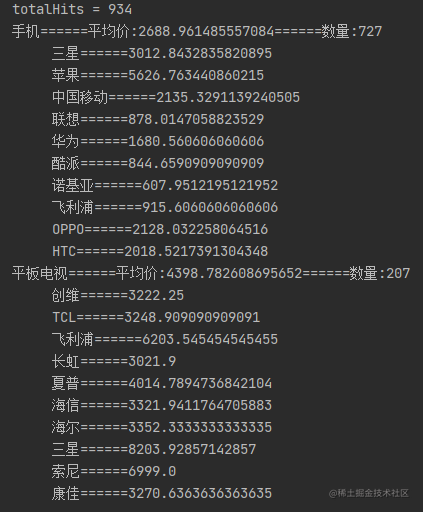
//获取总记录数
System.out.println("totalHits = " + searchResponse.getHits().getTotalHits().value);
// 获取聚合信息
Aggregations aggregations = searchResponse.getAggregations();
ParsedStringTerms categoryNameAgg = aggregations.get("categoryNameAgg");
//获取值返回
for (Terms.Bucket bucket : categoryNameAgg.getBuckets()) {
// 获取聚合后的分类名称
String categoryName = bucket.getKeyAsString();
// 获取聚合命中的文档数量
long docCount = bucket.getDocCount();
// 获取聚合后的分类的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg avgPrice = bucket.getAggregations().get("categoryNameAvgPrice");
System.out.println(categoryName + "======平均价:" + avgPrice.getValue() + "======数量:" + docCount);
ParsedStringTerms brandNameAgg = bucket.getAggregations().get("brandNameAgg");
for (Terms.Bucket brandeNameAggBucket : brandNameAgg.getBuckets()) {
// 获取聚合后的品牌名称
String brandName = brandeNameAggBucket.getKeyAsString();
// 获取聚合后的品牌的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg brandNameAvgPrice = brandeNameAggBucket.getAggregations().get("brandNameAvgPrice");
System.out.println(" " + brandName + "======" + brandNameAvgPrice.getValue());
分类: 后端 标签:
